[AI Interview] Tổng hợp 50 Câu Hỏi Phỏng Vấn Thường Gặp về Mô Hình Ngôn Ngữ Lớn (LLMs) - Phần 1
Xin chào các bạn! Hôm nay mình sẽ cùng các bạn khám phá một chủ đề không mới nhưng luôn nằm trong danh sách “nóng hổi” với những ai đang theo đuổi lĩnh vực AI. Đó chính là 50 câu hỏi phỏng vấn phổ biến nhất liên quan đến Mô Hình Ngôn Ngữ Lớn (LLM).
Với sự phát triển mạnh mẽ của Generative AI nói chung và các mô hình ngôn ngữ lớn nói riêng, nhu cầu tuyển dụng các vị trí như AI Engineer, Machine Learning Researcher ngày càng tăng cao. Trong các buổi phỏng vấn, nhà tuyển dụng không chỉ đánh giá qua kinh nghiệm mà còn dựa vào khả năng nắm vững các khái niệm cơ bản và chuyên sâu về LLM.
Bài viết này sẽ giúp bạn chuẩn bị tốt hơn bằng cách cung cấp những câu hỏi trọng tâm thường gặp, đi kèm với lời giải thích chi tiết để bạn dễ dàng hiểu và áp dụng. Dù bạn là người mới bắt đầu hay đã có kinh nghiệm, việc ôn luyện các câu hỏi này sẽ giúp bạn tự tin hơn khi đối diện với nhà tuyển dụng.
Câu hỏi 1: Tokenization là gì và tại sao nó quan trọng trong LLM?
Trả lời:
- Tokenization là quá trình chia nhỏ văn bản thành các đơn vị nhỏ hơn gọi là token, có thể là word, sub-word hoặc ký tự. Ví dụ, từ "tokenization" có thể được chia thành "token" và "ization". Đây là bước quan trọng vì LLM xử lý dữ liệu dưới dạng số đại diện cho các token này, giúp quản lý các ngôn ngữ khác nhau và cải thiện hiệu suất.
- Tokenization hiệu quả cho phép các mô hình xử lý nhiều ngôn ngữ khác nhau (multilingual), quản lý các từ ít khi gặp và giảm kích thước từ vựng (vocab size), giúp cải thiện cả hiệu quả và hiệu suất.

Câu hỏi 2: LoRA và QLoRA là gì?
Trả lời:
LoRA và QLoRA là các kỹ thuật được thiết kế để tối ưu hóa quá trình tinh chỉnh các Mô hình ngôn ngữ lớn (LLM), tập trung vào việc giảm mức sử dụng bộ nhớ (ví dụ giảm VRAM khi training với GPU) và nâng cao hiệu quả mà không ảnh hưởng đến hiệu suất trong các tác vụ Xử lý ngôn ngữ tự nhiên (NLP).
- LoRA (Low-Rank Adaptation): LoRA là một phương pháp fine-tuning (tinh chỉnh) hiệu quả về tham số, giới hạn các tham số mới có thể huấn luyện để điều chỉnh hành vi của mô hình mà không làm tăng kích thước tổng thể của nó. Bằng cách này, LoRA duy trì số lượng tham số ban đầu, giảm bớt việc sử dụng bộ nhớ thường đi kèm với việc huấn luyện các mô hình lớn. Phương pháp này hoạt động bằng cách thêm các ma trận thích ứng hạng thấp (low-rank matrix adaptations) vào các lớp hiện có của mô hình, cho phép cải thiện hiệu suất đáng kể trong khi vẫn giữ mức tiêu thụ tài nguyên ở mức kiểm soát. Điều này làm cho LoRA trở nên lý tưởng trong các môi trường có tài nguyên tính toán hạn chế nhưng vẫn yêu cầu độ chính xác cao của mô hình.

- QLoRA (Quantized LoRA): QLoRA phát triển dựa trên LoRA bằng cách tích hợp kỹ thuật lượng tử hóa (quantization) để tối ưu hóa việc sử dụng bộ nhớ hơn nữa. Phương pháp này sử dụng các kỹ thuật như 4-bit Normal Float, Double Quantization (Lượng tử hóa kép) và Paged Optimizers (Trình tối ưu hóa phân trang) để nén các tham số của mô hình và cải thiện hiệu quả tính toán. Bằng cách giảm độ chính xác của trọng số mô hình (ví dụ: từ 16-bit xuống 4-bit) trong khi vẫn giữ được phần lớn độ chính xác, QLoRA cho phép tinh chỉnh các mô hình ngôn ngữ lớn (LLMs) với dấu chân bộ nhớ tối thiểu. Phương pháp này đặc biệt hữu ích khi mở rộng quy mô các mô hình lớn, vì nó duy trì hiệu suất tương đương với các mô hình độ chính xác đầy đủ trong khi giảm đáng kể mức tiêu thụ tài nguyên.

Câu hỏi 3: Beam search là gì và nó khác gì so với giải mã tham lam (greedy decoding)?
Trả lời:
Beam search là một thuật toán tìm kiếm được sử dụng trong quá trình sinh văn bản nhằm tìm ra chuỗi từ có xác suất cao nhất. Thay vì chọn từ có xác suất cao nhất ở mỗi bước như giải mã tham lam (greedy decoding), beam search khám phá nhiều chuỗi khả thi song song, duy trì một tập hợp gồm k candidates (beams). Nó cân bằng giữa việc tìm kiếm các chuỗi có xác suất cao và khám phá các hướng đi thay thế. Điều này giúp tạo ra đầu ra mạch lạc và phù hợp với ngữ cảnh hơn, đặc biệt là trong các nhiệm vụ sinh văn bản dài.

Câu hỏi 4: Giải thích khái niệm temperature trong việc sinh văn bản của mô hình ngôn ngữ lớn (LLM).
Trả lời:
Temperature (T) là một siêu tham số (hyperparameter) điều chỉnh mức độ ngẫu nhiên trong quá trình sinh văn bản bằng cách thay đổi phân phối xác suất của các token tiếp theo có thể xuất hiện. Nhiệt độ thấp (gần 0) khiến mô hình trở nên rất quyết đoán, ưu tiên chọn các token có xác suất cao nhất. Ngược lại, nhiệt độ cao (trên 1) khuyến khích đa dạng hơn bằng cách làm phẳng phân phối, cho phép chọn cả những token có xác suất thấp hơn. Ví dụ, nhiệt độ 0.7 tạo ra sự cân bằng giữa tính sáng tạo và tính mạch lạc, phù hợp để sinh ra các nội dung đa dạng nhưng vẫn hợp lý.

Câu hỏi 5: Masked language modeling là gì, và nó đóng góp như thế nào vào quá trình pretraining của mô hình?
Trả lời:
Masked language modeling (MLM) là một mục tiêu (objective) huấn luyện trong đó một số token (từ hoặc ký tự) trong đầu vào được che ngẫu nhiên (masked), và mô hình phải dự đoán các token này dựa trên ngữ cảnh. Điều này buộc mô hình phải học các mối quan hệ ngữ cảnh giữa các từ, từ đó cải thiện khả năng hiểu ý nghĩa ngôn ngữ của nó. MLM thường được sử dụng trong các mô hình như BERT, mô hình được huấn luyện trước với mục tiêu này để phát triển khả năng hiểu sâu ngôn ngữ trước khi tinh chỉnh (fine-tuning) cho các tác vụ cụ thể.

Câu hỏi 6: Sequence-to-Sequence Models là gì?
Trả lời:
Sequence-to-Sequence (Seq2Seq) Models là một loại kiến trúc mạng nơ-ron được thiết kế để chuyển đổi một chuỗi dữ liệu đầu vào thành một chuỗi dữ liệu đầu ra. Các mô hình này thường được sử dụng trong các tác vụ mà độ dài của đầu vào và đầu ra có thể thay đổi, chẳng hạn như dịch máy (machine translation), tóm tắt văn bản (text summarization), và nhận dạng giọng nói (speech recognition).

Câu hỏi 7: Autoregressive models khác gì so với masked models trong huấn luyện LLM?
Trả lời:
Autoregressive models, chẳng hạn như GPT, tạo văn bản từng token một, với mỗi token được dự đoán dựa trên các token đã được tạo trước đó. Cách tiếp cận tuần tự này rất lý tưởng cho các tác vụ như sinh văn bản (text generation). Masked models, như BERT, dự đoán các token bị che ngẫu nhiên trong một câu, tận dụng ngữ cảnh từ cả bên trái và bên phải. Autoregressive models vượt trội trong các tác vụ tạo văn bản (generative tasks), trong khi masked models phù hợp hơn cho các tác vụ hiểu và phân loại (understanding and classification tasks).

Câu hỏi 8: Embeddings đóng vai trò gì trong LLMs, và chúng được khởi tạo như thế nào?
Trả lời:
Embeddings là các vector biểu diễn dạng liên tục và dày đặc (dense) của các token, giúp nắm bắt thông tin ngữ nghĩa (semantic) và cú pháp (syntactic). Chúng ánh xạ các token rời rạc (từ hoặc subwords) vào không gian nhiều chiều, làm cho chúng phù hợp để đưa vào mạng nơ-ron. Embeddings thường được khởi tạo ngẫu nhiên hoặc bằng các vector được huấn luyện trước như Word2Vec hoặc GloVe. Trong quá trình huấn luyện, các embeddings này được tinh chỉnh (fine-tuned) để nắm bắt các sắc thái đặc thù của tác vụ, cải thiện hiệu suất của mô hình trên các tác vụ ngôn ngữ khác nhau.

Câu hỏi 9: Next Sentence Prediction là gì và nó hữu ích như thế nào trong language modeling?
Trả lời:
Next Sentence Prediction (NSP) là một kỹ thuật quan trọng được sử dụng trong language modeling, đặc biệt là trong quá trình huấn luyện các mô hình lớn như BERT (Bidirectional Encoder Representations from Transformers). NSP giúp mô hình hiểu mối quan hệ giữa hai câu, điều này rất quan trọng cho các tác vụ như trả lời câu hỏi (question answering), tạo hội thoại (dialogue generation), và truy xuất thông tin (information retrieval).

Trong quá trình pre-training, mô hình được cung cấp hai câu:
- 50% thời gian training câu thứ hai là câu tiếp theo thực sự trong tài liệu (positive pairs).
- 50% thời gian training câu thứ hai là một câu ngẫu nhiên từ corpus (negative pairs).
Mô hình được huấn luyện để phân loại xem câu thứ hai (next sentence) có phải là câu đúng (positive) tiếp theo hay không. Nhiệm vụ phân loại nhị phân này được thực hiện song song với nhiệm vụ masked language modeling, giúp nâng cao khả năng hiểu ngôn ngữ tổng thể của mô hình.
Câu hỏi 10: Hãy giải thích sự khác biệt giữa top-k sampling và nucleus (top-p) sampling trong LLMs.
Trả lời:
-
Top-k sampling: Giới hạn lựa chọn của mô hình vào k token có xác suất cao nhất tại mỗi bước, tạo ra sự ngẫu nhiên có kiểm soát. Ví dụ, với k=10, mô hình chỉ xem xét 10 token có khả năng xảy ra cao nhất.
-
Nucleus sampling (top-p sampling): Tiếp cận linh hoạt hơn bằng cách chọn các token có tổng xác suất tích lũy vượt qua ngưỡng p (ví dụ: 0.9). Điều này cho phép bộ token được chọn thay đổi dựa trên ngữ cảnh, đồng thời cân bằng giữa sự đa dạng và tính mạch lạc của văn bản được tạo ra.

Câu hỏi 11: Prompt engineering ảnh hưởng như thế nào đến đầu ra của LLMs?
Trả lời:
-
Prompt engineering là quá trình tạo các câu lệnh đầu vào một cách khéo léo để hướng dẫn đầu ra của LLM hiệu quả hơn.
-
Vì LLM rất nhạy cảm với cách diễn đạt của câu lệnh, một prompt được thiết kế tốt có thể ảnh hưởng đáng kể đến chất lượng và độ phù hợp của câu trả lời.
- Ví dụ: Thêm ngữ cảnh hoặc hướng dẫn cụ thể trong prompt có thể cải thiện độ chính xác ở các tác vụ như tóm tắt văn bản (summarization) hoặc trả lời câu hỏi (question-answering).
-
Kỹ thuật này đặc biệt hữu ích trong các trường hợp zero-shot và few-shot learning, khi số lượng ví dụ cụ thể cho tác vụ là rất ít.

Câu hỏi 12: Làm thế nào để giảm thiểu hiện tượng catastrophic forgetting trong các mô hình ngôn ngữ lớn (LLMs)?
Trả lời:
Catastrophic forgetting xảy ra khi một LLM quên các tác vụ đã học trước đó trong quá trình học các tác vụ mới, làm giảm tính linh hoạt của nó. Một số chiến lược để giảm thiểu vấn đề này gồm:
**1. Rehearsal methods:((
- Huấn luyện lại mô hình trên một tập hợp dữ liệu kết hợp giữa dữ liệu cũ và mới.
- Giúp mô hình duy trì kiến thức về các tác vụ trước đó.
2. Elastic Weight Consolidation (EWC):
- Gán mức độ quan trọng cho một số trọng số của mô hình.
- Bảo vệ kiến thức quan trọng trong khi học các tác vụ mới.
3. Modular approaches:
- Sử dụng các kỹ thuật như Progressive Neural Networks (ProgNet) và Optimized Fixed Expansion Layers (OFELs).
- Thêm các module mới dành riêng cho các tác vụ mới, giúp mô hình học mà không ghi đè kiến thức trước đó.

Câu hỏi 13: Model distillation là gì và nó được áp dụng như thế nào đối với LLMs?
Trả lời:
Model distillation là một kỹ thuật mà một mô hình nhỏ hơn, đơn giản hơn (student model) được huấn luyện để tái tạo hành vi của một mô hình lớn hơn, phức tạp hơn (teacher model). Trong bối cảnh LLMs (Large Language Models), mô hình học viên học từ các dự đoán mềm (soft predictions) của mô hình giáo viên, thay vì chỉ dựa vào nhãn cứng (hard labels), qua đó nắm bắt được kiến thức sâu sắc và tinh tế. Cách tiếp cận này giúp giảm yêu cầu về tài nguyên tính toán và bộ nhớ, đồng thời vẫn duy trì hiệu suất tương tự, lý tưởng để triển khai các LLMs trên các thiết bị hạn chế về tài nguyên.
Câu hỏi 14: LLMs xử lý Out-of-vocabulary (các từ ngoài bộ từ vựng) như thế nào?
Trả lời:
Từ ngoài bộ từ vựng (out-of-vocabulary words - OOV) là các từ mà mô hình không gặp phải trong quá trình huấn luyện. LLMs (Large Language Models) giải quyết vấn đề này thông qua các kỹ thuật phân tách từ con (subword tokenization) như Byte-Pair Encoding (BPE) và WordPiece. Những phương pháp này chia các từ OOV thành các đơn vị từ con nhỏ hơn và đã biết. Ví dụ, từ “unhappiness” có thể được phân tách thành “un,” “happi,” và “ness.” Cách này giúp mô hình hiểu và tạo ra các từ mà nó chưa từng gặp trước đó bằng cách tận dụng các thành phần từ con này.
Câu hỏi 15: Kiến trúc Transformer vượt qua những thách thức của các mô hình Sequence-to-Sequence truyền thống như thế nào?
Trả lời:
Kiến trúc Transformer vượt qua các hạn chế chính của các mô hình Sequence-to-Sequence (Seq2Seq) truyền thống bằng nhiều cách:
-
Xử lý song song (Parallelization): Các mô hình Seq2Seq xử lý tuần tự, dẫn đến tốc độ huấn luyện chậm. Transformers sử dụng self-attention để xử lý các token song song, tăng tốc độ huấn luyện và suy luận.
-
Phụ thuộc dài (Long-Range Dependencies): Các mô hình Seq2Seq gặp khó khăn với các phụ thuộc dài hạn. Transformers xử lý hiệu quả những vấn đề này nhờ self-attention, cho phép mô hình tập trung vào bất kỳ phần nào của chuỗi bất kể khoảng cách.
-
Mã hóa vị trí (Positional Encoding): Vì Transformers xử lý toàn bộ chuỗi cùng lúc, positional encoding được sử dụng để giúp mô hình hiểu thứ tự của các token.
-
Hiệu suất và khả năng mở rộng (Efficiency and Scalability): Seq2Seq chậm hơn khi mở rộng do xử lý tuần tự. Transformers, nhờ khả năng xử lý song song, mở rộng tốt hơn cho các tập dữ liệu lớn và chuỗi dài.
-
Context Bottleneck: Seq2Seq sử dụng một vector ngữ cảnh duy nhất, giới hạn thông tin truyền tải. Transformers cho phép decoder tham chiếu tất cả đầu ra của encoder, cải thiện khả năng giữ ngữ cảnh.

Câu hỏi 16: Overfitting trong machine learning là gì và làm thế nào để ngăn chặn nó?
Trả lời:
- Overfitting xảy ra khi một mô hình machine learning hoạt động tốt trên dữ liệu huấn luyện nhưng kém trên dữ liệu chưa từng thấy hoặc dữ liệu kiểm tra. Điều này thường xảy ra vì mô hình không chỉ học được các mẫu cơ bản trong dữ liệu mà còn học cả nhiễu và các điểm ngoại lệ, làm cho mô hình trở nên quá phức tạp và quá phụ thuộc vào tập huấn luyện. Kết quả là mô hình không thể tổng quát hóa tốt trên dữ liệu mới.

-
Các kỹ thuật ngăn chặn overfitting:
![image.png]()
- Regularization (L1, L2): Thêm một khoản phạt vào hàm mất mát để hạn chế mô hình quá phức tạp. L1 (Lasso) hỗ trợ chọn đặc trưng, trong khi L2 (Ridge) làm mượt các trọng số.
- Dropout: Trong các mạng nơ-ron, dropout vô hiệu hóa ngẫu nhiên một phần các neuron trong quá trình huấn luyện, giúp ngăn mô hình phụ thuộc quá mức vào các nút cụ thể.
- Data Augmentation: Mở rộng tập dữ liệu huấn luyện bằng các biến thể nhỏ, như lật hoặc xoay hình ảnh, để tăng cường khả năng chống chịu của mô hình.
- Early Stopping: Theo dõi hiệu suất của mô hình trên dữ liệu xác thực và dừng huấn luyện khi mất mát trên tập xác thực không còn giảm.
- Sử dụng mô hình đơn giản hơn (Simpler Models): Giảm độ phức tạp của mô hình bằng cách giảm số lượng đặc trưng, tham số, hoặc lớp có thể giúp tránh overfitting.

Câu hỏi 17: Generative models và Discriminative models là gì?
Trả lời:
Trong NLP, generative models và discriminative models là hai loại mô hình quan trọng được sử dụng cho nhiều tác vụ khác nhau.

-
Generative models: Các mô hình này học phân phối dữ liệu cơ bản và tạo ra các mẫu mới từ phân phối đó. Chúng mô hình hóa xác suất kết hợp (joint probability distribution) giữa đầu vào và đầu ra, với mục tiêu tối đa hóa khả năng xảy ra của dữ liệu quan sát được. Ví dụ phổ biến là mô hình ngôn ngữ (language model), dự đoán từ tiếp theo trong một chuỗi dựa trên các từ trước đó.
-
Discriminative models: Các mô hình này tập trung vào việc học một ranh giới quyết định giữa các lớp khác nhau trong không gian đầu vào - đầu ra. Chúng mô hình hóa xác suất có điều kiện (conditional probability) của đầu ra dựa trên đầu vào, với mục tiêu phân loại chính xác các ví dụ mới. Ví dụ là mô hình phân tích cảm xúc (sentiment analysis model), phân loại văn bản thành tích cực, tiêu cực hoặc trung tính dựa trên nội dung.
Tóm lại, generative models tạo ra dữ liệu, trong khi discriminative models phân loại dữ liệu đó.
Câu hỏi 18: GPT-4 khác gì so với các phiên bản trước đó như GPT-3 về khả năng và ứng dụng?
Trả lời:
GPT-4 mang đến nhiều cải tiến so với GPT-3, cả về khả năng lẫn ứng dụng:
- Khả năng hiểu tốt hơn (Improved Understanding): GPT-4 có khoảng 1 nghìn tỷ tham số, vượt xa GPT-3 với 175 tỷ tham số, giúp cải thiện khả năng xử lý thông tin phức tạp.
- Khả năng đa phương tiện (Multimodal Capabilities): GPT-4 có thể xử lý cả văn bản và hình ảnh, một bước tiến lớn so với GPT-3, chỉ hỗ trợ văn bản.
- Hiểu ngữ cảnh lớn hơn (Larger Context Window): GPT-4 xử lý đầu vào với ngữ cảnh lên đến 25.000 token, so với giới hạn 4.096 token của GPT-3.
- Độ chính xác và tinh chỉnh tốt hơn (Better Accuracy and Fine-Tuning): GPT-4 được tinh chỉnh để chính xác hơn về mặt thông tin, giảm khả năng tạo ra nội dung sai lệch hoặc gây hại.
- Hỗ trợ đa ngôn ngữ tốt hơn (Language Support): GPT-4 cải thiện hiệu suất đa ngôn ngữ, hỗ trợ tới 26 ngôn ngữ với độ chính xác cao hơn, đặc biệt vượt trội trong các ngôn ngữ không phải tiếng Anh so với GPT-3.

Câu hỏi 19: Positional encodings là gì trong ngữ cảnh của các mô hình ngôn ngữ lớn (LLMs)?
Trả lời:
Positional encodings rất quan trọng trong các Large Language Models (LLMs) để khắc phục hạn chế của kiến trúc transformer trong việc nắm bắt thứ tự chuỗi. Vì transformers xử lý các token đồng thời thông qua cơ chế self-attention, chúng không thể tự hiểu thứ tự của các token. Positional encodings cung cấp thông tin cần thiết để mô hình hiểu được trình tự của các từ.
Cơ chế hoạt động:
- Phương pháp cộng (Additive Approach): Positional encodings được cộng thêm vào các vector nhúng từ (word embeddings), kết hợp thông tin vị trí với biểu diễn từ tĩnh.
- Hàm sin và cosin (Sinusoidal Function): Nhiều LLMs, chẳng hạn như dòng GPT, sử dụng các hàm lượng giác để tạo ra positional encodings.
Công thức:
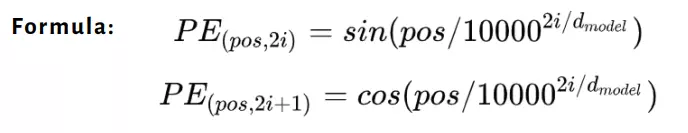
Trong đó:
poslà vị trí trong chuỗi.ilà chỉ số chiều (0 ≤i<d_model/2).d_modellà số chiều của mô hình.
Câu hỏi 20: Multi-head attention là gì?
Trả lời:
Multi-head attention là một sự cải tiến của cơ chế single-head attention, cho phép mô hình tập trung vào thông tin từ nhiều không gian biểu diễn con cùng lúc, đồng thời chú ý đến các vị trí khác nhau trong dữ liệu. Thay vì chỉ sử dụng một cơ chế chú ý duy nhất, multi-head attention chiếu các queries, keys, và values vào nhiều không gian con (ký hiệu là h lần) thông qua các phép biến đổi tuyến tính học được.
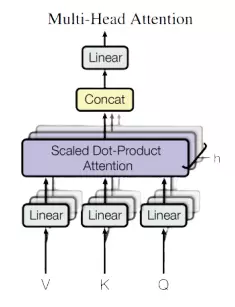
Cách thứ hoạt động:
- Áp dụng attention function song song (parallel) trên các phiên bản được chiếu của queries, keys, và values.
- Tạo ra nhiều vector đầu ra.
- Kết hợp các vector đầu ra này để tạo ra kết quả cuối cùng có kích thước
d_v.
Cách tiếp cận này cải thiện khả năng của mô hình trong việc nắm bắt các mẫu phức tạp và mối quan hệ trong dữ liệu.
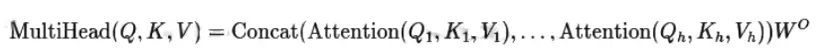
Câu hỏi 21: Hàm softmax và giải thích vai trò của nó trong các cơ chế chú ý.
Trả lời:
Hàm softmax chuyển đổi một vector các số thực thành một phân phối xác suất. Với vector đầu vào , hàm softmax cho phần tử thứ được định nghĩa như sau:
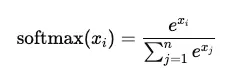
Đặc điểm:
- Đầu ra của softmax nằm trong khoảng từ 0 đến 1.
- Tổng các giá trị đầu ra luôn bằng 1, cho phép diễn giải chúng như các xác suất.
Vai trò trong cơ chế attention (attention mechanisms):
- Trong cơ chế attention, hàm softmax được áp dụng lên các điểm số chú ý (attention scores) để chuẩn hóa chúng. Điều này:
- Đảm bảo rằng các trọng số chú ý có thể được giải thích như mức độ quan trọng của các token khác nhau.
- Cho phép mô hình tập trung nhiều hơn vào các phần liên quan nhất của chuỗi đầu vào, giúp cải thiện hiệu quả khi tạo ra đầu ra.
Câu hỏi 22: Tích vô hướng (dot product) được sử dụng trong self-attention như thế nào, và ý nghĩa của nó đối với hiệu quả tính toán là gì?
Trả lời:
Trong self-attention, tích vô hướng (dot product) được sử dụng để tính toán mức độ tương đồng giữa các vector query (Q) và key (K). Các điểm số attention được tính như sau:
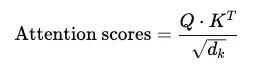
Trong đó là chiều không gian của các vector key. Tích vô hướng đo lường sự tương quan giữa các token, giúp mô hình xác định token nào cần tập trung hơn.
Mặc dù phương pháp này hiệu quả, độ phức tạp bậc hai () theo độ dài chuỗi (sequence length) là một thách thức đối với các chuỗi dài. Điều này đã thúc đẩy sự phát triển của các phương pháp xấp xỉ hiệu quả hơn.
Câu hỏi 23: Giải thích cross-entropy loss và tại sao nó thường được sử dụng trong mô hình hóa ngôn ngữ (language modeling).
Trả lời:
Cross-entropy loss đo lường sự khác biệt giữa phân phối xác suất dự đoán và phân phối thực (dạng mã hóa one-hot của token đúng). Nó được định nghĩa như sau:
Trong đó $ y_i$ là nhãn thực (true label), là xác suất dự đoán.
Cross-entropy loss phạt nặng các dự đoán sai, khuyến khích mô hình đưa ra các xác suất gần 1 hơn cho lớp đúng. Trong mô hình hóa ngôn ngữ (language modeling), nó đảm bảo rằng mô hình dự đoán đúng token trong chuỗi với độ tự tin cao.
Câu hỏi 24: Làm thế nào để tính gradient của hàm mất mát (loss function) đối với các vector embedding?
Trả lời:
Để tính gradient của hàm mất mát 𝐿 đối với một vector embedding 𝐸, ta áp dụng quy tắc dây chuyền (chain rule):
Trong đó:
- là gradient của hàm mất mát với đầu ra logits.
- là gradient của logits với vector embedding.
Quá trình backpropagation sẽ lan truyền các gradient này qua các tầng của mạng, điều chỉnh các vector embedding để giảm thiểu hàm mất mát.
Câu hỏi 25: Vai trò của ma trận Jacobian trong quá trình backpropagation qua mô hình transformer là gì?
Trả lời:
Ma trận Jacobian biểu diễn các đạo hàm riêng phần của một hàm vector đối với các đầu vào của nó. Trong backpropagation, nó cho thấy cách mỗi phần tử của vector đầu ra thay đổi tương ứng với mỗi đầu vào.
Đối với mô hình transformer, ma trận Jacobian đóng vai trò quan trọng trong việc tính gradient cho các đầu ra đa chiều, đảm bảo rằng mỗi tham số (bao gồm cả trọng số và embedding) được cập nhật chính xác để giảm thiểu hàm mất mát.
All Rights Reserved
