[Architecture] Search Engine & Vector Database: Khi tìm kiếm từ khóa (Keyword) đã là dĩ vãng
Chào anh em lại là mình đây

đụng đến Search Engine là đụng đến "chén cơm" của các hệ thống E-commerce và nội dung lớn rồi.
Thời đại bây giờ, nếu người dùng gõ "sữa rửa mặt cho da mụn" mà hệ thống của bạn không trả về những chai "gel làm sạch giảm tiết bã nhờn" (vì không khớp từ khóa), thì bạn đã mất đi một khách hàng. Đó là lúc kỹ thuật tìm kiếm truyền thống bộc lộ tử huyệt, và Vector Database vươn lên như một đấng cứu thế.
Bài viết này không dành cho những ai chỉ biết viết câu query SELECT * FROM products WHERE name LIKE '%keyword%'. Chúng ta sẽ mổ xẻ kiến trúc bên dưới của Search Engine, từ Inverted Index cho đến Semantic Search, và cách build một hệ thống Hybrid Search chuẩn Enterprise.
Bắt đầu nhé!!!

Lời mở đầu: Cú tát từ trải nghiệm người dùng (UX)
Bạn là một Backend Developer. Bạn hì hục dựng lên một con Elasticsearch cluster tốn cả đống RAM. Bạn tự hào vì response time cho API tìm kiếm chỉ mất 15ms.
Nhưng rồi team Business phàn nàn:
- Khách tìm chữ "nước tẩy trang" -> Kết quả ra 0, vì trong database product name của bạn ghi là "Micellar Water".
- Khách gõ sai chính tả "kem chng nang" -> Kết quả ra 0.
Lúc này, bạn nhận ra: Máy móc chỉ hiểu ký tự, nó không hiểu NGỮ NGHĨA. Elasticsearch (với thuật toán BM25) bản chất là đếm số lần xuất hiện của từ khóa (Term Frequency). Dù bạn có config Synonyms (từ đồng nghĩa) hay fuzzy search đi chăng nữa, thì việc duy trì một bộ từ điển khổng lồ cho hàng triệu sản phẩm là một cơn ác mộng bảo trì.

Đã đến lúc chúng ta phải thay đổi mô hình tư duy: Chuyển từ Lexical Search (Tìm theo từ khóa) sang Semantic Search (Tìm theo ngữ nghĩa) với vũ khí tối thượng mang tên Vector Database.
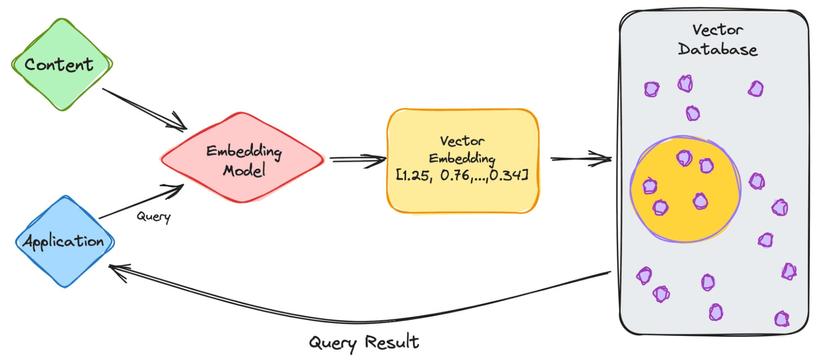
1. Vector Database là cái quái gì? (Bản chất của Semantic Search)

Để máy tính hiểu được "Nước tẩy trang" và "Micellar Water" là một, chúng ta phải nhờ đến AI (cụ thể là các mô hình Embedding như của OpenAI, Cohere, hoặc mô hình open-source như all-MiniLM-L6-v2).
Embedding là gì?
Nó là một quá trình "ép" một đoạn text, một hình ảnh thành một mảng các con số (Vector) trong một không gian đa chiều (thường là 384, 768 hoặc 1536 chiều).
Những câu có ý nghĩa giống nhau sẽ có tọa độ nằm gần nhau trong không gian đó.
- Vector A ("Nước tẩy trang"):
[0.12, -0.45, 0.89, ...] - Vector B ("Micellar Water"):
[0.11, -0.42, 0.88, ...] - Vector C ("Bàn phím cơ"):
[-0.99, 0.55, -0.12, ...]
Vector Database (Pinecone, Milvus, Qdrant, pgvector) sinh ra để lưu trữ hàng triệu cái mảng số này và thực hiện một nhiệm vụ duy nhất: Tìm ra các vector có khoảng cách gần nhất với vector truy vấn. Thuật toán phổ biến nhất để đo khoảng cách này là Cosine Similarity.
2. Code Demo: Cách một luồng Vector Search hoạt động
Hãy quên SQL đi. Đây là cách hệ thống của bạn sẽ chạy khi user gõ tìm kiếm:
Bước 1: Lưu trữ dữ liệu (Ingestion) Khi bạn thêm một sản phẩm mới vào DB, bạn phải gọi AI để lấy Vector và lưu vào Vector DB.
// Giả mã (Pseudo-code) trong Service của Laravel
public function indexProduct($product)
{
// 1. Gộp các thông tin quan trọng thành một chuỗi văn bản chứa ngữ nghĩa
$textToEmbed = "Tên: {$product->name}. Mô tả: {$product->description}. Phù hợp: {$product->skin_type}";
// 2. Gọi AI Model (ví dụ OpenAI) để biến text thành Vector (mảng 1536 số)
$vector = OpenAI::embeddings()->create([
'model' => 'text-embedding-ada-002',
'input' => $textToEmbed,
])->embeddings[0]->embedding;
// 3. Lưu vào Vector DB (Ví dụ dùng PostgreSQL + pgvector)
DB::table('products')->where('id', $product->id)->update([
'embedding' => json_encode($vector) // Cột này có type là vector(1536)
]);
}
Bước 2: Tìm kiếm (Querying) User gõ "đồ rửa mặt cho da nhạy cảm".
public function search($keyword)
{
// 1. Biến câu query của user thành Vector
$queryVector = OpenAI::embeddings()->create([
'input' => $keyword,
])->embeddings[0]->embedding;
// 2. Dùng toán tử tính Cosine Similarity (<=> trong pgvector) để tìm Top 5 sản phẩm gần nghĩa nhất
$queryVectorString = '[' . implode(',', $queryVector) . ']';
$results = DB::select("
SELECT id, name, description,
1 - (embedding <=> '$queryVectorString') AS similarity_score
FROM products
ORDER BY embedding <=> '$queryVectorString'
LIMIT 5
");
return $results;
}
Kết quả: Dù chữ "đồ rửa mặt" và "da nhạy cảm" không hề xuất hiện chính xác trong tên sản phẩm, AI vẫn hiểu ngữ nghĩa và Vector DB sẽ lôi ra đúng chai sữa rửa mặt Cetaphil hoặc Cerave. Tuyệt vời!

3. Kiến trúc Enterprise: Hybrid Search - Đừng vứt bỏ Elasticsearch vội!
Đọc đến đây, nhiều anh em vội vàng đòi đập bỏ Elasticsearch/Meilisearch để đắp Vector DB vào. Khoan đã, đây là cái bẫy chết người!

Vector Database cực giỏi trong việc "đoán ý", nhưng nó lại vô dụng trong việc tìm kiếm chính xác (Exact Match). Nếu khách hàng gõ chính xác mã SKU "MAC-LIP-001", Vector DB có thể trả về một thỏi son khác có ngữ nghĩa tương tự thay vì chính xác thỏi son có mã đó.
Giải pháp hạng nặng của các Big Tech: HYBRID SEARCH.
Chúng ta sẽ chạy song song 2 luồng:
- Keyword Search (Elasticsearch/BM25): Bắt chính xác mã SKU, tên thương hiệu, từ khóa cụ thể.
- Semantic Search (Vector DB): Bắt ngữ nghĩa, từ đồng nghĩa, ý định người dùng.
Thuật toán dung hợp: RRF (Reciprocal Rank Fusion) Sau khi 2 DB trả về 2 tập kết quả khác nhau, tầng Backend (hoặc trực tiếp trên DB hỗ trợ Hybrid) sẽ dùng RRF để chấm điểm lại:
(Trong đó k là một hằng số, thường = 60)
Thằng nào vừa xếp hạng cao ở Keyword, vừa xếp hạng cao ở Ngữ nghĩa sẽ được đẩy lên Top 1. Hệ thống của bạn lúc này đã trở thành một cỗ máy tìm kiếm bất bại.

Tóm lại
- Lexical Search (SQL LIKE, BM25): Tốt cho tìm kiếm chính xác, rẽ tiền, nhưng ngu ngơ về ngữ nghĩa.
- Vector DB (Semantic Search): Tốt cho tìm kiếm ý định, bỏ qua sai chính tả, nhưng kém trong việc khớp mã chính xác và tốn tiền gọi AI model.
- Hybrid Search: Trùm cuối. Kiến trúc bắt buộc phải có của các hệ thống E-commerce và nội dung lớn trong kỷ nguyên AI.
Đừng làm một thợ gõ code chỉ biết CRUD. Hãy hiểu sâu về luồng dữ liệu và cách các hệ thống lớn giải quyết bài toán UX. Nếu anh em thấy bài mổ xẻ này "đã ngứa", hãy để lại 1 upvote nhé!
All rights reserved
