Chiến lược Scaling PostgreSQL của OpenAI: Phân tích từ PGConf.dev 2025
Tại sự kiện PGConf.dev 2025 vừa qua, Bohan Zhang từ OpenAI đã có một bài chia sẻ cực kỳ hay ho về những kinh nghiệm xương máu (best practices) khi sử dụng PostgreSQL, hé lộ cách mà một trong những gã khổng lồ công nghệ hiện nay vận hành hệ thống database của mình.
Một câu chốt hạ đắt giá từ Bohan:
"Tại OpenAI, chúng tôi sử dụng kiến trúc
unshardedvớione writervàmultiple readers. Điều này chứng minh rằng PostgreSQL hoàn toàn có thể scale hiệu quả cho những workload có lượng read cực lớn (heavy read)." PGConf.dev 2025, Bohan Zhang, OpenAI
 Cho anh em nào chưa biết, Bohan Zhang là thành viên của team Infrastructure tại OpenAI, từng là học trò của giáo sư lừng danh Andy Pavlo tại CMU và cũng là đồng sáng lập của OtterTune.
Cho anh em nào chưa biết, Bohan Zhang là thành viên của team Infrastructure tại OpenAI, từng là học trò của giáo sư lừng danh Andy Pavlo tại CMU và cũng là đồng sáng lập của OtterTune.
Bối cảnh: PostgreSQL tại OpenAI
Tại OpenAI, PostgreSQL chính là database xương sống, phục vụ cho phần lớn các hệ thống quan trọng. Nói không ngoa, nếu PostgreSQL "sập", rất nhiều dịch vụ cốt lõi của OpenAI sẽ bị ảnh hưởng trực tiếp. Thực tế, các sự cố liên quan đến PostgreSQL cũng đã từng khiến ChatGPT chao đảo không ít lần trong quá khứ.

OpenAI đang sử dụng dịch vụ managed database trên Azure (Azure Database for PostgreSQL). Họ dùng kiến trúc primary-replica replication kinh điển của PostgreSQL và hoàn toàn không sharding. Kiến trúc này gồm một primary database và hàng chục replicas. Đối với một dịch vụ có hàng triệu active users như OpenAI, khả năng scale rõ ràng là một bài toán cực lớn.
Thách thức không hề nhỏ
Với kiến trúc primary-replica của OpenAI, việc scale cho các tác vụ đọc (read) khá thoải mái. Tuy nhiên, các tác vụ ghi (write) lại nhanh chóng trở thành bottleneck. Để giải quyết, OpenAI đã phải tìm mọi cách để tối ưu, ví dụ như offloading write loads (chuyển bớt các tác vụ ghi đi nơi khác) bất cứ khi nào có thể, và hạn chế tối đa việc thêm service mới vào primary database.

Bản thân thiết kế Multi-Version Concurrency Control (MVCC) của PostgreSQL vốn có một vài điểm yếu cố hữu như table bloat và index bloat. Việc "tuning" tiến trình vacuuming cũng rất đau đầu. Lý do là vì mỗi lần write, database sẽ tạo ra một version mới cho record (kể cả khi chỉ là update), và việc truy cập index cũng đòi hỏi thêm bước visibility check. Những vấn đề này tạo ra thách thức lớn khi scale read replicas: ví dụ, khi tăng Write-Ahead Logging (WAL) có thể dẫn đến replication lag lớn hơn, và khi số lượng replica tăng lên, network bandwidth lại có thể trở thành bottleneck mới.
Các giải pháp OpenAI đã áp dụng
Để xử lý các vấn đề trên, team OpenAI đã tập trung vào nhiều mảng:
1. Kiểm soát tải trên Primary Database
Chiến lược đầu tiên và quan trọng nhất là giảm và san đều tải ghi (write request) cho primary database:
- Chuyển các tác vụ ghi không quá quan trọng sang các hệ thống khác.
- Giảm thiểu các lệnh ghi không cần thiết ngay từ tầng application.
- Áp dụng cơ chế
lazy writesđể dàn đều các đợt ghi dữ liệu đột biến. - Kiểm soát chặt chẽ tần suất khi thực hiện
data backfilling.
Bên cạnh đó, OpenAI cố gắng đẩy tối đa các request đọc sang replicas. Đối với những truy vấn đọc bắt buộc phải chạy trên primary (ví dụ khi nằm trong một transaction đọc-ghi), việc tối ưu hiệu năng của chúng là yếu tố sống còn.

2. Tối ưu tầng Query
Tiếp theo, OpenAI tập trung vào việc cải thiện query layer:
- Kiểm soát thời gian transaction: Các
long transactionslà kẻ thù củagarbage collectionnó thường gây cản trở quá trình dọn rác và ngốn tài nguyên hệ thống. OpenAI xử lý bằng cách cấu hình nhiều loạitimeoutskhác nhau (từsession level,statement levelđếnclient level) để ngăn chặn tình trạng"Idle in Transaction"kéo dài. - Tối ưu query phức tạp: Những
multi-join queries"khủng" (ví dụ join 12 bảng cùng lúc) được phân tích và tối ưu đặc biệt để cải thiện hiệu suất. - Cẩn trọng với "phép thuật" từ ORM: Bài chia sẻ nhấn mạnh rằng việc lạm dụng
ORM(Object-Relational Mapping) thường sinh ra các query không hiệu quả. Lời khuyên của OpenAI là phải dùngORMmột cách rất cẩn trọng và có chọn lọc.

3. Giải quyết Single Point of Failure
Primary database chính là một single point of failure: nếu nó gặp sự cố, mọi tác vụ ghi sẽ bị chặn hoàn toàn. Tuy nhiên, may mắn là với kiến trúc multi-replica, hệ thống vẫn có khả năng đọc ngay cả khi có sự cố.
- Nếu một
read-only replica"chết", các ứng dụng có thể dễ dàng chuyển sang đọc từ mộtreplicakhác mà không bị gián đoạn. - Phần lớn các request quan trọng của OpenAI là
read-only, điều này giúp hệ thống duy trì hoạt động ngay cả khiprimary databasetạm thời "down".
OpenAI còn đi xa hơn bằng cách phân chia độ ưu tiên của request:
- Các
high-priority requestsđược định tuyến đến một cụmread-only replicaschuyên dụng. - Cách làm này giúp bảo vệ các request quan trọng không bị ảnh hưởng bởi các request có độ ưu tiên thấp hơn (
low-priority requests).

4. Quản lý Schema một cách chặt chẽ
Giải pháp thứ tư là chỉ cho phép các lightweight schema change (thay đổi schema không gây tác động lớn) trên cluster này. Cụ thể:
- Nghiêm cấm việc tạo bảng mới hay đưa workload mới vào hệ thống.
- Cho phép thêm/xóa column (với timeout chỉ
5 giây), nhưng cấm mọi thao tác yêu cầufull table rewrite. - Cho phép tạo/xóa index, nhưng bắt buộc phải dùng tùy chọn
CONCURRENTLY.
Một vấn đề "đau đầu" khác được đề cập là các long-running query (>1s) có thể liên tục block các schema change, khiến chúng bị fail. Giải pháp là tầng ứng dụng phải tối ưu hoặc chuyển các query này sang read replica để không làm ảnh hưởng đến việc thay đổi schema trên primary.
Kết quả đạt được
- Scale thành công Azure-hosted PostgreSQL, xử lý hàng triệu QPS (cả read và write) trên toàn bộ cluster, chống lưng cho các dịch vụ cốt lõi của OpenAI.
- Thêm hàng chục
replicas(khoảng 40) mà không làm tăngreplication lag. - Triển khai
read-only replicasở nhiều khu vực địa lý khác nhau nhưng vẫn giữ được độ trễ thấp. - Trong 9 tháng qua, chỉ có duy nhất một sự cố nghiêm trọng (
SEV0 incident) liên quan đến PostgreSQL. - Dự trữ đủ capacity cho sự tăng trưởng trong tương lai.
Case study về sự cố thực tế
OpenAI cũng chia sẻ một vài case study về các sự cố họ đã gặp phải:
- Case đầu tiên là về
cache failuredẫn đến hiệu ứng domino (cascading effect), ảnh hưởng toàn bộ hệ thống.

- Sự cố thứ hai đặc biệt thú vị: khi
CPU usagetăng vọt, một bug đã xuất hiện. Điều đáng nói là ngay cả khi CPU đã trở lại bình thường, tiến trìnhWALSendervẫn bị kẹt trong một vòng lặp vô hạn thay vì gửiWAL logsđếnreplica, dẫn đếnreplication lagngày càng tăng.

Đề xuất cải tiến cho PostgreSQL
Cuối cùng, Bohan đã đưa ra một số "đặt hàng" tới cộng đồng phát triển PostgreSQL:
- Quản lý Index: Index không dùng đến vừa gây
write amplification, vừa tăngmaintenance overhead. OpenAI muốn loại bỏ chúng, nhưng để giảm rủi ro, họ đề xuất một tính năngDisableindex. Nó sẽ cho phép theo dõiperformance metricsđể đảm bảo hệ thống ổn định trước khi quyết định xóa vĩnh viễn. - Observability: Hiện tại,
pg_stat_statementschỉ cung cấpaverage response time, thiếu các chỉ số quan trọng nhưp95,p99 latency. OpenAI mong muốn có các metrics chi tiết hơn nhưhistogramsvàpercentile latenciesđể giám sát hiệu suất tốt hơn. - Lịch sử Schema Changes: OpenAI đề xuất PostgreSQL nên có cơ chế ghi lại lịch sử các thay đổi schema, như việc thêm/xóa column và các DDL operations khác.
- Làm rõ ngữ nghĩa Monitoring View: Họ phát hiện một session có
state = Activevàwait_event = ClientReadtồn tại hơn 2 giờ. Điều này cho thấy connection vẫn hoạt động rất lâu sau khi query bắt đầu, và những connection này không bịidle_in_transaction timeoutsngắt. Họ muốn biết liệu đây có phải là bug và làm sao để xử lý. - Tối ưu Default Parameters: OpenAI nhận xét rằng các giá trị mặc định của PostgreSQL đã quá lỗi thời. Họ đề xuất nên có các tham số mặc định tốt hơn, hoặc cơ chế
heuristic-based settingsđể tự động điều chỉnh cho phù hợp với phần cứng hiện đại.
Góc nhìn từ chuyên gia
Bình luận của Lao Feng
Tuy PGConf.Dev 2025 là sự kiện cho developer, nhưng những chia sẻ thực tế từ người dùng như OpenAI luôn là "đặc sản". Những insight này đặc biệt hữu ích cho các core developer, vì nhiều người trong số họ chưa có cơ hội trải nghiệm PostgreSQL trong các môi trường production khắc nghiệt.
Từ cuối năm 2017, Lao Feng đã quản lý hàng chục PostgreSQL cluster tại Tantan, một trong những hệ thống lớn và phức tạp nhất ở Trung Quốc thời điểm đó. Core cluster lớn nhất của họ khi đó dùng 1 master và 33 replicas, xử lý khoảng 400,000 QPS. Lao Feng cũng gặp bottleneck tương tự ở single-node write performance và đã giải quyết bằng cách sharding database và sharding table ở tầng ứng dụng.
Có thể nói, những bài toán và giải pháp mà OpenAI chia sẻ không quá mới lạ, team của Lao Feng cũng đã "cày" qua hết rồi. Tất nhiên, khác biệt lớn nhất là phần cứng ngày nay mạnh hơn rất nhiều so với 8 năm trước. Điều này cho phép một startup như OpenAI dùng một PostgreSQL cluster duy nhất, không cần sharding hay partitioning để vận hành toàn bộ hệ thống. Đây là một minh chứng rõ ràng cho quan điểm rằng distributed databases đôi khi là một giải pháp không cần thiết (overkill).
Hiện tại, OpenAI đang dùng PostgreSQL trên Azure với cấu hình server cao cấp. Hệ thống có hơn 40 replicas (bao gồm cả cross-region replicas) và xử lý khoảng 1 triệu QPS (read + write). Họ dùng Datadog để giám sát và truy cập cluster qua PgBouncer đặt phía client trong Kubernetes.
Vì là khách hàng strategic-level, team Azure PostgreSQL luôn hỗ trợ OpenAI rất sát sao. Tuy nhiên, điều này cho thấy ngay cả khi dùng dịch vụ database hàng đầu, bạn vẫn cần có chuyên môn sâu về cả application và vận hành. Đội ngũ của OpenAI rất xuất sắc, nhưng họ vẫn gặp phải những pitfalls khi vận hành PostgreSQL trong thực tế.
High availability không được đề cập, có lẽ vì Azure PostgreSQL đã lo phần này. Khá thú vị là dù rủng rỉnh tiền bạc, OpenAI vẫn nhận xét rằng Datadog "đắt một cách vô lý".
Sau hội nghị, Lao Feng đã có một buổi trò chuyện dài với Bohan và hai nhà sáng lập database khác. Rất tiếc là không thể chia sẻ chi tiết về cuộc trò chuyện thú vị đó!

Q&A của Lao Feng
Về những vấn đề và tính năng mà Bohan đề xuất, Lao Feng đã có một vài phản hồi. Thực tế, hầu hết các chức năng mà OpenAI cần đã tồn tại trong hệ sinh thái PostgreSQL, chỉ là chúng có thể không có sẵn trong core PostgreSQL hoặc trên Azure Database for PostgreSQL.
Về việc Disable Indexes
Thực ra PostgreSQL có tính năng này. Bạn chỉ cần set trường indisvalid thành false trong system catalog pg_index. Thao tác này sẽ khiến planner bỏ qua index, nhưng nó vẫn được maintain trong các DML operations. Về mặt kỹ thuật, đây chính là cơ chế được dùng khi tạo concurrent index.
Tuy nhiên, có một cái khó là OpenAI không thể dùng cách này, vì Azure Database for PostgreSQL không cấp quyền superuser, nên không thể sửa trực tiếp system catalogs.
Quay lại vấn đề gốc: sợ xóa nhầm index. Bài toán này có thể giải quyết đơn giản hơn bằng cách theo dõi monitoring views để chắc chắn index không được sử dụng trên cả primary và replicas.
Trong hệ thống Pigsty monitoring, bạn có thể quan sát trực tiếp quá trình live index switching:
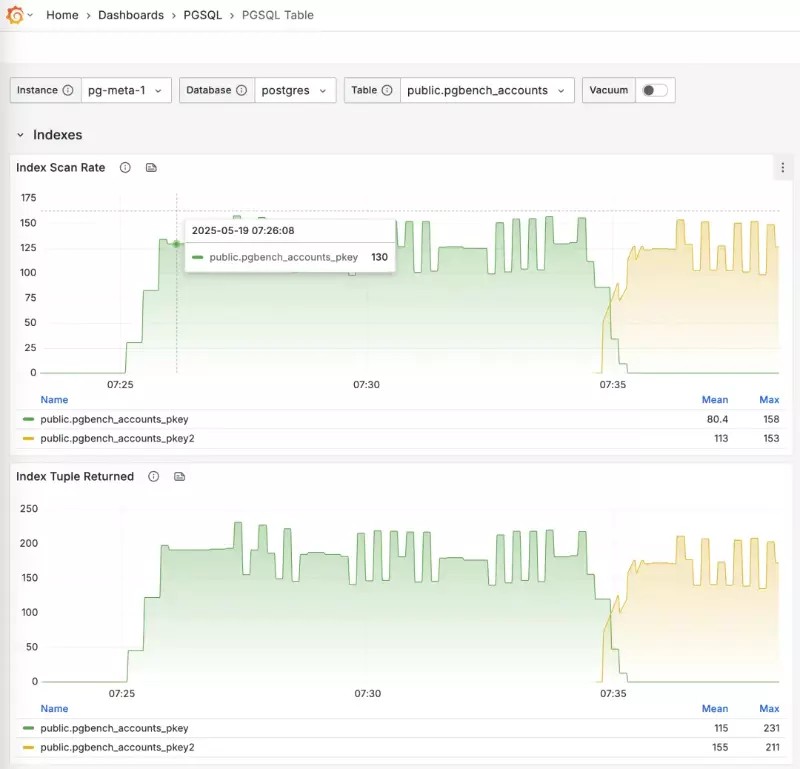
-- Tạo một index mới song song
CREATE UNIQUE INDEX CONCURRENTLY pgbench_accounts_pkey2
ON pgbench_accounts USING BTREE(aid);
-- Đánh dấu index cũ là invalid (sẽ không được dùng) nhưng vẫn được maintain
UPDATE pg_index SET indisvalid = false
WHERE indexrelid = 'pgbench_accounts_pkey'::regclass;
Về Observability
pg_stat_statements khó có thể sớm hỗ trợ P95/P99, vì nó sẽ làm tăng memory footprint của extension lên hàng chục lần. Dù server hiện nay thừa sức xử lý, nhưng nhiều người vẫn còn khá bảo thủ.
Tuy nhiên, vẫn có các giải pháp thay thế:
- Extension
pg_stat_monitorcung cấppercentile latency metricschi tiết (dù cần cân nhắc performance overhead). - Dùng
eBPFđể thu thậpRT metricsmột cách thụ động. - Thêm logic giám sát độ trễ query ở tầng data access của application.
Giải pháp tối ưu nhất có lẽ là dùng eBPF, nhưng vì OpenAI dùng Azure PostgreSQL và không có quyền truy cập vào server, nên phương án này bất khả thi.
Về việc ghi lại Schema Change
Thực ra, PostgreSQL logs đã hỗ trợ tính năng này. Chỉ cần set log_statement thành ddl, mọi DDL sẽ được ghi lại. Extension pgaudit cũng làm được điều tương tự.
Nếu OpenAI muốn một system view có thể truy vấn bằng SQL, họ có thể dùng CREATE EVENT TRIGGER để log DDL event vào một bảng. Extension pg_ddl_historization giúp làm việc này dễ hơn nhiều.
Đáng tiếc là việc tạo event triggers cũng yêu cầu quyền superuser. AWS RDS có một số xử lý đặc biệt để cho phép, nhưng Azure PostgreSQL dường như không hỗ trợ.
Về ngữ nghĩa của Monitoring View
Trong ví dụ của OpenAI, State = Active và WaitEvent = ClientRead thường có nghĩa là process đang đợi input từ client, ví dụ như trong một lệnh COPY FROM STDIN, hoặc do TCP blocking. Khó có thể kết luận đây là bug hay không nếu không biết connection đó đang thực sự làm gì.
Giải pháp cho vấn đề này là gì? Trong Pigsty, khi truy cập PostgreSQL qua HAProxy, có thể set maximum connection lifespan (ví dụ: 24 giờ) ở tầng load balancer. Khi một connection vượt ngưỡng này, nó sẽ bị ngắt. Lý tưởng nhất là client-side connection pool nên chủ động quản lý và ngắt các connection cũ.
Về Default Parameters
Ai cũng đồng ý rằng default parameters của PostgreSQL cực kỳ "cổ lỗ sĩ". Ưu điểm là PostgreSQL có thể chạy trên hầu hết mọi môi trường. Nhược điểm? Lao Feng từng thấy production setup có 1TB RAM nhưng vẫn chạy với cấu hình default 256MB memory.
Nhìn chung, đây không hẳn là điều tệ. Vấn đề có thể được giải quyết bằng dynamic configuration tốt hơn. Cả Azure Database for Postgres và Pigsty đều đã có các heuristics để thiết lập tham số ban đầu một cách hợp lý.
Nên Self-Hosting?
Thách thức thực sự của OpenAI không đến từ bản thân PostgreSQL, mà từ những hạn chế của một dịch vụ managed trên Azure. Một giải pháp là chuyển sang IaaS của Azure hoặc cloud khác để tự dựng self-hosted PostgreSQL clusters trên các instance có local NVMe SSD.
Thực tế, Pigsty mà Lao Feng xây dựng chính là để giải quyết các bài toán của PostgreSQL ở quy mô tương tự, về cơ bản nó là một self-hosted Azure Database for Postgres solution. Rất nhiều vấn đề mà OpenAI gặp phải đều đã có giải pháp trong Pigsty - một dự án open-source và miễn phí.
Nếu OpenAI quan tâm, Lao Feng rất sẵn lòng hỗ trợ. Tuy nhiên, với một công ty đang phát triển như vũ bão, việc tối ưu infrastructure database có thể chưa phải là ưu tiên hàng đầu. May mắn là họ có những DBA PostgreSQL xuất sắc, những người có thể tiếp tục thúc đẩy và cải thiện hệ thống hiện tại.
Bài viết này được dịch và biên tập từ bài báo của Lao Feng:
All rights reserved
