
[Advanced-LLM] Điều gì thật sự "ẩn dấu" sau "sự suy luận" của LLM ? Vén màn một chút sự thật....
Mở đầu.
Hiện tại đang là 31/5🫠, mình về quê, chưa biết làm gì cả, thôi thì viết thêm một bài nữa kết thúc tháng 5 nào 😉.
Thì 3 bài trước đó mình đã viết loanh quanh về khả năng của LLM. Vậy thì chính xác model LLM đã làm gì, điều gì khiến nó trở lên lên thông minh như vậy ? Tại sao nó làm được nhưng điều tưởng chừng chỉ có con người mới làm được ? Liệu LLM đã thật sự suy luận hay AGI đang đến gần ?
Có rất nhiều những câu hỏi xung quanh được đặt ra, tự đó sinh ra rất nhiều giả định, lý thuyết và nghiên cứu về khả năng của LLM.
Thông thường đa phần từ góc độ của engineer, LLM giống như một Black Box, chỉ cần input và rồi nó sẽ nhả ra output, một ngày đẹp trời, chúng ta sử dụng những magic word và waoo LLM ra những thứ thần kỳ thú vị. Vậy thứ chính xác trong cái black box mà không thể kiểm soát đó là cái gì ? và thứ gì ẩn dấu sâu bên trong mô hình đó, liệu có phải là một bộ não thiên tài, siêu nhiên, siêu việt đang đánh lừa chúng ta? Cùng phân tích và vén màn một chút sự thật về khả năng reasoning của mô hình nhé.
HOLD UP :
- Đây chỉ là một bài viết overview nhỏ cho những cái mà mình đang đọc gần đây, không mang tính chất paper explain hay những thứ phân tích sâu như các bài trước, đây chỉ là một góc nhìn nhỏ từ mình, một engineer chính hiệu. Hãy cân nhắc trước khi đọc.
- Mình đọc khá nhiều paper và source khác nhau, và bị mất dấu mất nhiều source rồi nên mình ko để vô ref hết được. Đây chỉ là một vài ý mình tổng hợp cũng như suy luận từ góc nhìn của mình, nên chắc chắc nó không thể chính xác và không có thực nghiệm cũng như kiểm chứng.
- Đây là một sở thích nhỏ tự củng cố solution của bản thân, và cũng chỉ là sự tò mò đưa mình đi vọc vạch mọi thứ, for fun =)) nên là hãy cứ chill thôi nhé.
Oke, Let's move on.
Một chút phân tích.
Một chút nhìn nhận.
Thật ra thì khi nhìn vào model LLm thì nó cũng chỉ là một decoder only transfromer thôi, phải chăng thì nó có thêm các biến thể, sự kết hợp thêm vô với audio và image rồi vẫn sinh ra xác suất ở text hay các dạng khác, ... Về cơ bản nó là một mô hình xác suất, LLM cố gắng học data training distribution, và nhả ra những cái tương tự distribution mà nó thấy, từ đó thì các khả năng mà LLM có được sẽ xuất hiện một cách tương tự như data đầu vào, có code thì học code, có toán thì học toán, có suy luận thì học suy luận.
Nói một cách kỹ thuật hơn một chút thì nó là Probabilistic Pattern Matching - Là việc bạn đưa vào LLM một task hay prompt, ... thì nó cố gắng tìm kiếm dữ liệu có liên quan và gần nhất trong tập dữ liệu huấn luyện. ➝ Hay mình hay gọi vui vui đó là các template mà trainer nhét vào LLM.
Phân tích một chút template của LLM.
Nhìn một ví dụ điển hình mà ibm reasoning có từng mô tả (link tại ref), không chính xác lắm nhưng đại ý như thế này :
- An mua hoa quả, thứ 2 An mua 10 quả táo, thứ 3 An mua thêm 15 quả táo nữa, nhưng trong đó có 5 quả táo xanh. Hỏi An đã mua bao nhiêu quả táo ? ➝ Mô hình sẽ đưa ra : 10 + 15 - 5 = 20. Trong khi kết quả thực tế là 10 + 15 = 25.
Vậy thì điều gì thể hiện ở đây : trong khi 5 quả táo xanh kia không ảnh hưởng đến việc mua 15 quả táo ở thứ 3, nhưng LLM vẫn trừ đi 5. Họ lập luận rằng data training về math phần lớn : nhưng thông tin được cung cấp sẽ có một cái gì đấy liên quan đến đề bài, hay luôn luôn có một tác dụng và mô hình LLM được học để làm như vậy nên khi tính nó vẫn trừ 5 đi.
Và thậm chí LLM có thể đưa ra đáp án đúng mà không cần hiểu đúng cái cái khái niệm cơ bản.
Nhìn thêm một ví dụ khác.
LLM không thật sự suy nghĩ theo cách mà ta tưởng tượng ...
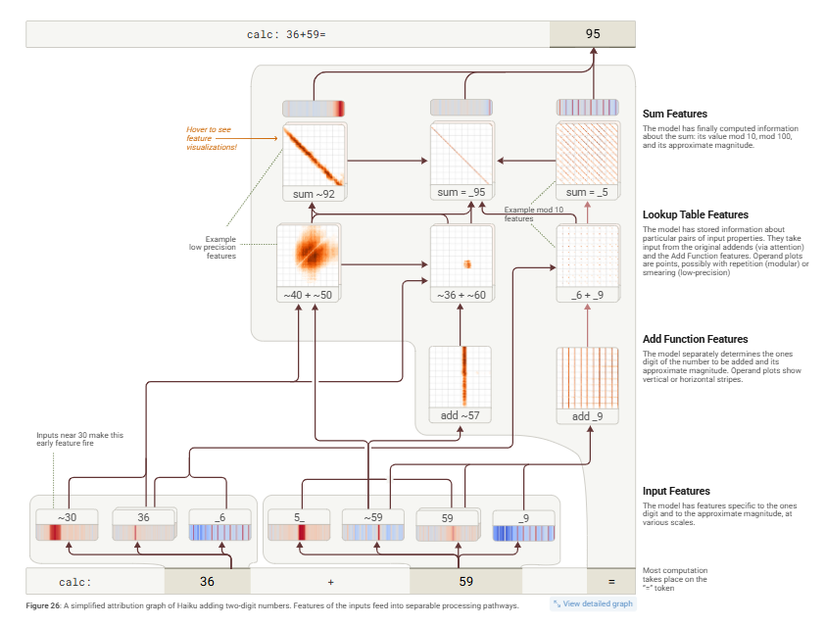
Nhìn thêm một ví dụ về phép cộng hai số 36 + 59 = .... người ta đang cố kiểm tra xem cách hoạt động thật sự của mô hình LLM là gì (thực nghiệm trên claude 3.5 haiku), họ cố mô phỏng nó lên à nhận ra nó không thật sự như cái cách mà chúng ta vẫn hay nghĩ, mà nó kiểu (ví dụ ở ảnh trên):
- Các phép tính được thực hiện một cách đồng thời.
- Một số phần chỉ tập trung vào các chữ số cuối cùng, số 6 và số 9, và biết rằng 6 + 9 = 15
- Một số phần khác lại được dùng để ước tính độ lớn của câu trả lời, chẳng hạn là 39 cộng với 50 gì đó và có thể bằng 80 hoặc 90.
- Nó thậm chí còn tạo thành một
cheat sheetđược mô tả là một dạng lưu trữ thông tin được tính toán trước đó, giống như các node lưu trữ thông tin. - Sau đó mô hình kết hợp tất cả các kết quả từ các ước tính khác nhau và thực hiện đồng thời và kết quả cuối cùng được tính toàn là 95 được dự đoán ra.
Và sau đó, họ có hỏi lại LLM rằng làm cách nào để tính toán ra được nó, và câu trả lời như sau :

LLM đưa ra một câu trả lời rất human và kết quả chính xác, nhưng rõ ràng theo phân tích trong chính nội tại mô hình thì nó hoàn toàn không làm theo như vậy. Việc đưa ra một dãy CoT nhìn có vẻ là giống cách nó làm nhưng hoàn toàn là không.
Vậy nhưng việc như hiện tại cải thiện về mặt CoT hay Long CoT vốn không thật sự cải thiện khả năng reasoning thật sự trong nội tại của LLM (implicit reasoning), nó chỉ là một phần nguỵ trang và để cho human lầm tưởng rằng đó thật sự là cách nó làm và tin theo.
Và nhìn nhận một cách cụ thể hơn việc sử dụng ngôn ngữ để diễn tả sự suy luận của LLM, nhược điểm chính khi sử dụng ngôn ngữ để suy luận :
- Ngôn ngữ không được thiết kế nhằm mục đích tối ưu hoá cho việc suy luận. Con người không hoàn toàn suy luận thông qua lời nói. Ví dụ : bạn nhìn một bản đồ mê cung, bạn tự có thể suy nghĩ tìm được đầu vào, đầu ra, thậm chí là con đường đi ra khỏi mê cung nhanh nhất mà không cần nói.
- LLM tập trung nhiều vào việc sử dụng ngôn ngữ chỉ để chúng ta hiểu, chứ không thật sự tập trung vào sự hiệu quả.
Vậy việc bắt model Think step by step ... Có thật sự giúp mô hình suy luận không ? ... Theo những research gần đây thì nó vốn không có quá nhiều ý nghĩa, tuy nhiên đây cũng là một cách tiếp cận làm tăng khả năng suy luận của model LLM sau một khoảng thời gian chững lại.
Vậy LLM đang reasoning hay planning đây ? Có một vài chỗ cho rằng việc mô hình đang reasoning thật ra chỉ là việc nó đang planning và CoT cũng là một dạng planning., nào là chia nhỏ task thành các sub task, sub task thành các sub task bé hơn, ... rồi giải quyết từng phần một, ... Ở đây là khái niệm planning LLm mà ..., mình có gán link ở ref để mọi người đọc nhé.
Kết luận.
Vậy mô hình đã có khả năng suy luận ? Và điểm khác biệt chính giữa Suy luận và Mô phỏng giống con người là gì ?
Theo IBM suy luận cần có :
- Consicious : Hiểu biết chủ quan.
- Goal driven : Có mục tiêu
- Subjective understanding : Có ý thích.
- Adaptability : Khả năng thích ứng.
Còn mô phỏng : như LLM, sinh ra các response có vẻ ngoài của suy nghĩ, bằng cách fit pattern với thought data training nhưng không có :
- Actual awareness : Nhận thức thực tế.
- Actual comprehension : Không có sự hiểu biết thực tế.
- Actual purpose : Không có mục tiêu thực tế.
Vậy thì thứ gì, điều gì sẽ đưa LLM không phải mô phỏng mà thật sự trở thành suy luận thật sự?
- Symbolic Understanding : Như đã nói con người không chỉ suy luận bằng ngôn ngữ, mà còn thao tác với các biểu tượng trừu tượng và các mối quan hệ, LLm thiếu các cơ chế suy luận biểu tượng thật sự.
- Causal inference : Suy luận cần đòi hỏi về hiểu biết về nguyên nhân, kết quả, không chỉ là các mối tương quan thống kê, mô hình cần có khả năng suy luận phải suy ra các nguyên tắc cơ bản từ dữ liệu thay vì chỉ dự đoán từ tiếp theo.
- Self-Reflection and Metacognition : Con người liên tục đánh giá quá trình suy nghĩ của mình bằng cách tự hỏi kết luận này có hơp lý không ? Trong khi đó thì LLM không có cơ chế tự phản ánh. Việc xây dựng các mô hình tự đánh giá nghiêm túc đầu ra của mình là một bước quan trọng.
- Common Sence and Intuition : LLM không có trả nghiệm thực tế để định hình trực giác và chúng không thể dễ dàng nhận ra những điều vô lý mà con người có thể nhận ra ngay lập tức.
- Counterfactual Thinking : Tư duy của con người thường liên quan đến việc tự hỏi điều gì sẽ xảy ra nếu mọi thứ khác đi ? LLM gặp khó khăn với các kịch bản nếu thì vì chúng bị giới hạn bởi dữ liệu mà chúng được huấn luyện. Để các mô hình LLM giống con người trong những tình huống này, cần mô phỏng các kịch bản giả định và hiểu cách thay đổi trong các biến số có thể ảnh hưởng đến kết quả. Và chúng ta cũng cần thử nghiệm các khả năng khác nhau và đưa ra những hiểu bớt mới, thay vì chỉ dự đoán trên những gì đã thấy, nếu không LLM sẽ chỉ có thể làm việc với những gì đã được học. Và không bao giờ xảy ra Out of distribution.
Oke, thế thôi nhỉ, hẹn mọi người ở một ngày đẹp trời nào đó khác 🫠🫠 và cùng phân tích kỹ hơn theo một vài paper mình thấy khá hay ....
Note.
- Bài viết này, mình không đi sâu cũng không viết dài, đúng như tiêu đề Mình chỉ vén màn một chút sự thật và hiểu sao cho đúng nhiêu đó thôi.
- Mình có note lại các nguồn ở đây, mọi người quan tâm thì có thì đọc thêm. Mình vẫn đang đọc chưa hiểu hoàn toàn, nào thấy được cái gì đủ wow thì sẽ chia sẻ cho mọi người ở bài tiếp theo.
Reference.
- https://arxiv.org/abs/2505.13775
- https://www.ibm.com/think/topics/ai-reasoning
- https://transformer-circuits.pub/2025/attribution-graphs/biology.html
- https://www.unite.ai/llms-are-not-reasoning-theyre-just-really-good-at-planning/
- https://arxiv.org/abs/2504.09858
- https://www.youtube.com/watch?v=Dk36u4NGeSU&t=302s
All rights reserved
