[LLM 101] Tìm hiểu RLHF trong InstructGPT và Llama 2
Giới thiệu
Nếu từng làm về LLM thì hẳn bạn sẽ không còn thấy xa lạ gì với RLHF (Reinforcement Learning with Human Feedback). RLHF đóng một vai trò quan trọng trong quá trình training và finetuning 1 mô hình LLM, giúp tăng chất lượng các câu trả lời của mô hình dựa vào feedback từ con người.
Trong bài viết này, chúng ta sẽ cùng nhau tìm hiểu cơ chế hoạt động của RLHF và các phiên bản thay thế của phương pháp này 
Quy trình training LLM
Thông thường, các mô hình LLM transformer-based như ChatGPT, Llama 2, Llama 3 thường trải qua 3 bước training chính, đó là: Pretraining, Supervised finetuning và Alignment.
Trong giai đoạn pretraining, các mô hình sẽ được training trên một lượng dữ liệu không được gán nhãn khổng lồ. Giai đoạn này tận dụng lượng dữ liệu văn bản lớn từ các nguồn đa dạng như sách, trang web và các nguồn văn bản được publish khác

Trong quá trình pretraining, mô hình học cách dự đoán token tiếp theo trong một câu, nhờ đó xây dựng được tri thức toàn diện về các pattern ngôn ngữ, ngữ pháp và các sự kiện, thông tin cơ bản về thế giới. Sau quá trình này, ta có một mô hình ngôn ngữ đa dụng với nền tảng từ vựng và khái niệm rộng và sâu.

Tiếp theo đến giai đoạn Supervised finetuning (SFT). Ở giai đoạn này, ta sẽ finetune các mô hình pretraining để nó follow tốt hơn các instruction cụ thể (như hình trên) Các mô hình pretraining sẽ tiếp tục được training trên một tập dữ liệu custom gồm các sample được gán nhãn.
Về cơ bản, trong quá trình Supervised finetuining, mô hình vẫn học cách dự đoán token tiếp theo. Tuy nhiên, khác với giai đoạn Pretraining, ở đây chúng ta sử dụng các cặp instruction - output như trong hình. Ta có instruction là đầu vào đưa cho mô hình (có thể bổ sung thêm input tuỳ yêu cầu bài toán). Phản hồi là output mà mô hình cần đưa ra.
Ví dụ, với cặp instruction - output sau:
-
Instruction: "Write a limerick about a pelican."
-
Output: "There once was a pelican so fine..."
Mô hình sẽ nhận đầu vào là instruction "Write a limerick about a pelican" và dự đoán token tiếp theo cho output "There once was a pelican so fine...".
Dù cả hai giai đoạn đều có mục tiêu là dự đoán token tiếp theo, nhưng SFT thường dùng các tập dữ liệu nhỏ hơn nhiều so với Pretraining vì yêu cầu phải có cặp instruction-output thay vì chỉ đơn thuần là văn bản thô. Việc thu thập dữ liệu cho SFT thường tốn rất nhiều thời gian và "lúa"
Cuối cùng, ta sẽ tới giai đoạn alignment. Như tên gọi, đây là giai đoạn "căn chỉnh" lại mô hình LLM sao cho chất lượng phản hồi tốt hơn và sát với mong muốn của người dùng hơn
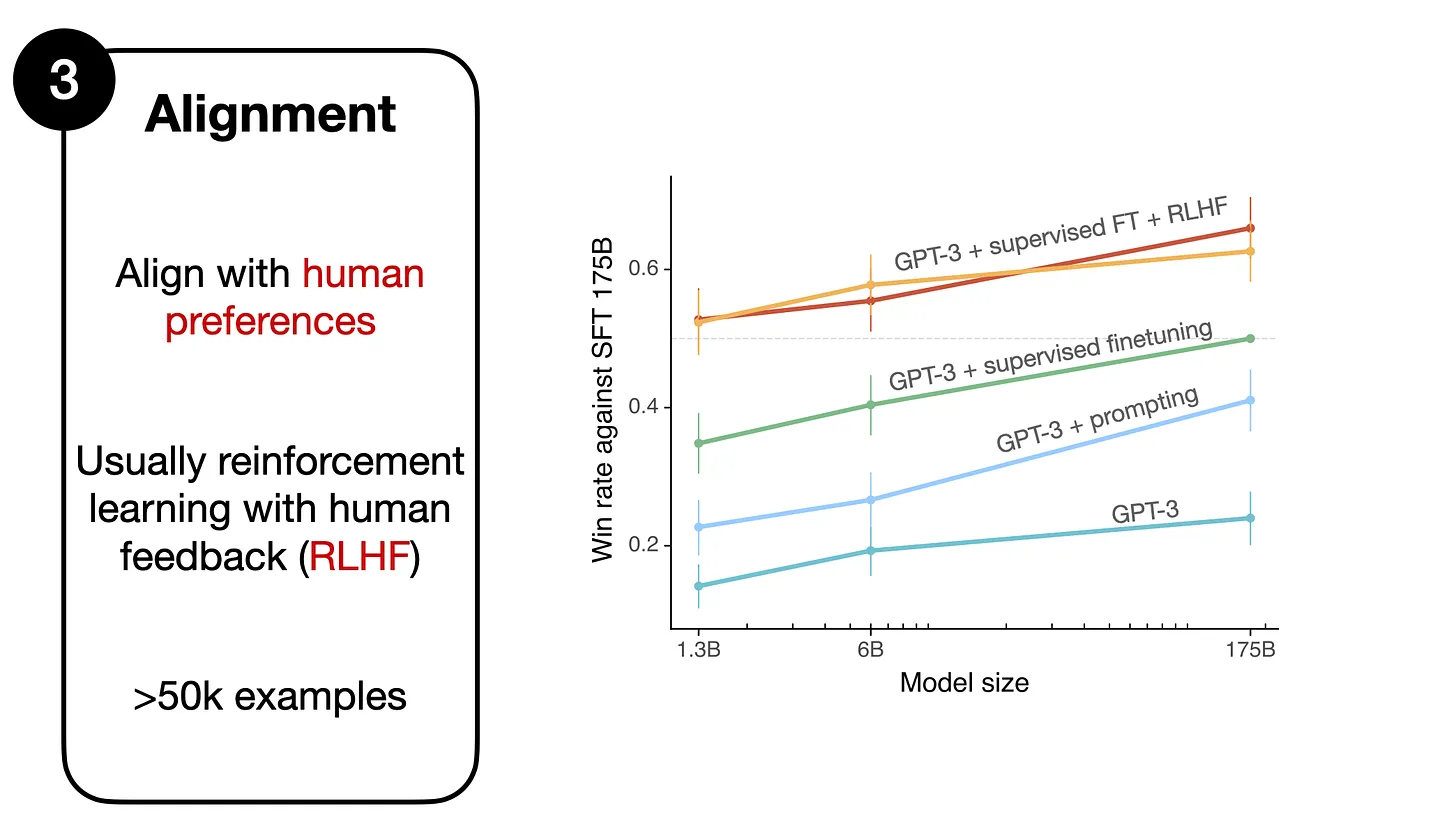
Trong hình trên, từ bài báo InstructGPT, có thể thấy rằng mô hình GPT-3 dùng SFT được so sánh với các phương pháp khác. Cụ thể:
- Mô hình GPT-3 cơ bản nằm ở dưới cùng.
- Phương pháp sử dụng thêm prompt (GPT-3 + prompting) cải thiện 1 chút so với mô hình cơ bản.
- SFT (GPT-3 + supervised finetuning) còn tốt hơn khi sử dụng prompt.
- Hiệu suất tốt nhất đạt được từ mô hình GPT-3 khi dùng SFT và RLHF ("GPT-3 + supervised finetuning + RLHF") — hai đường ở trên cùng của biểu đồ. (Có 2 đường vì các tác giả đã thử nghiệm 2 quy trình sampling khác nhau).
Reinforcement Learning with Human Feedback (RLHF)
Về cơ bản, RLHF sẽ gồm có 3 bước như sau:
- Bước 1: Supervised finetuning mô hình pretrained
- Bước 2: Tạo 1 reward model
- Bước 3: Finetuning thông qua proximal policy optimization (PPO)
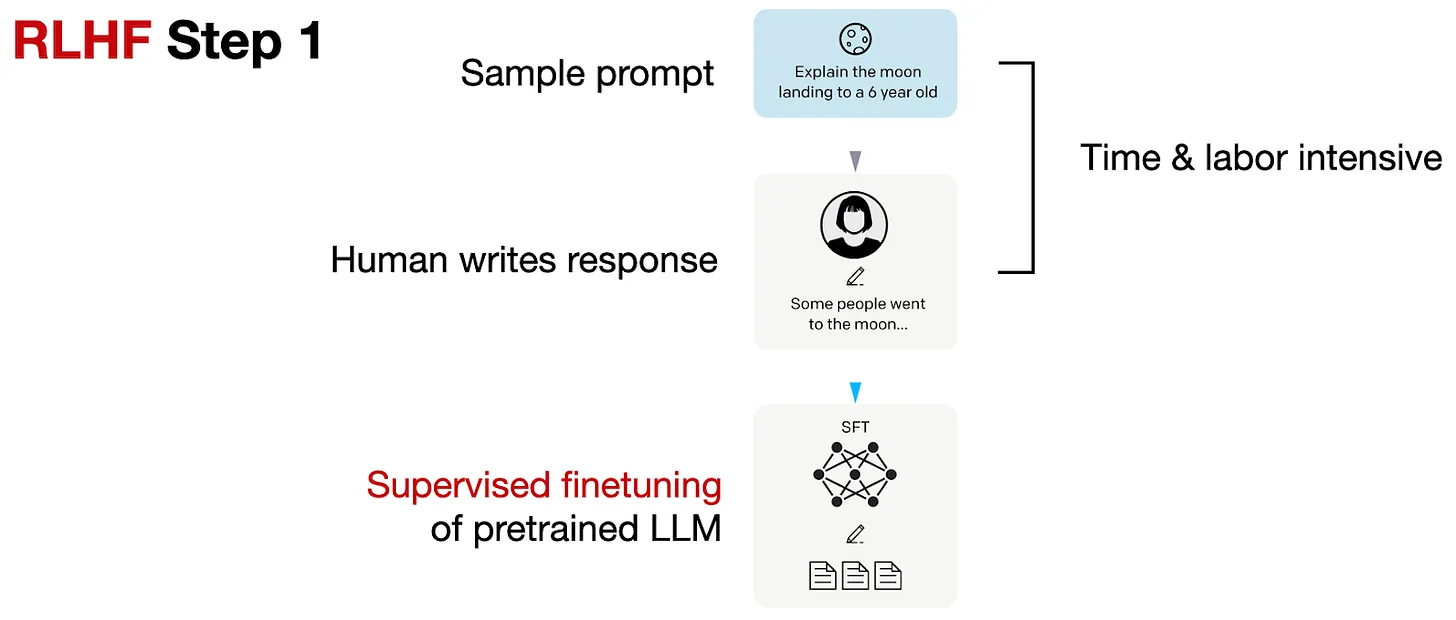
Các bạn có thể quan sát bước 1 trong hình trên. Đây là bước chúng ta sẽ thực hiện Supervised finetuning trên 1 pretrained model. Trong bước này, chúng ta sẽ tạo 1 sample prompts và sử dụng nguồn lực là con người để viết một phản hồi chất lượng cho prompt đó. Sau đó, chúng ta sẽ sử dụng các mẫu dữ liệu này để thực hiện SFT.
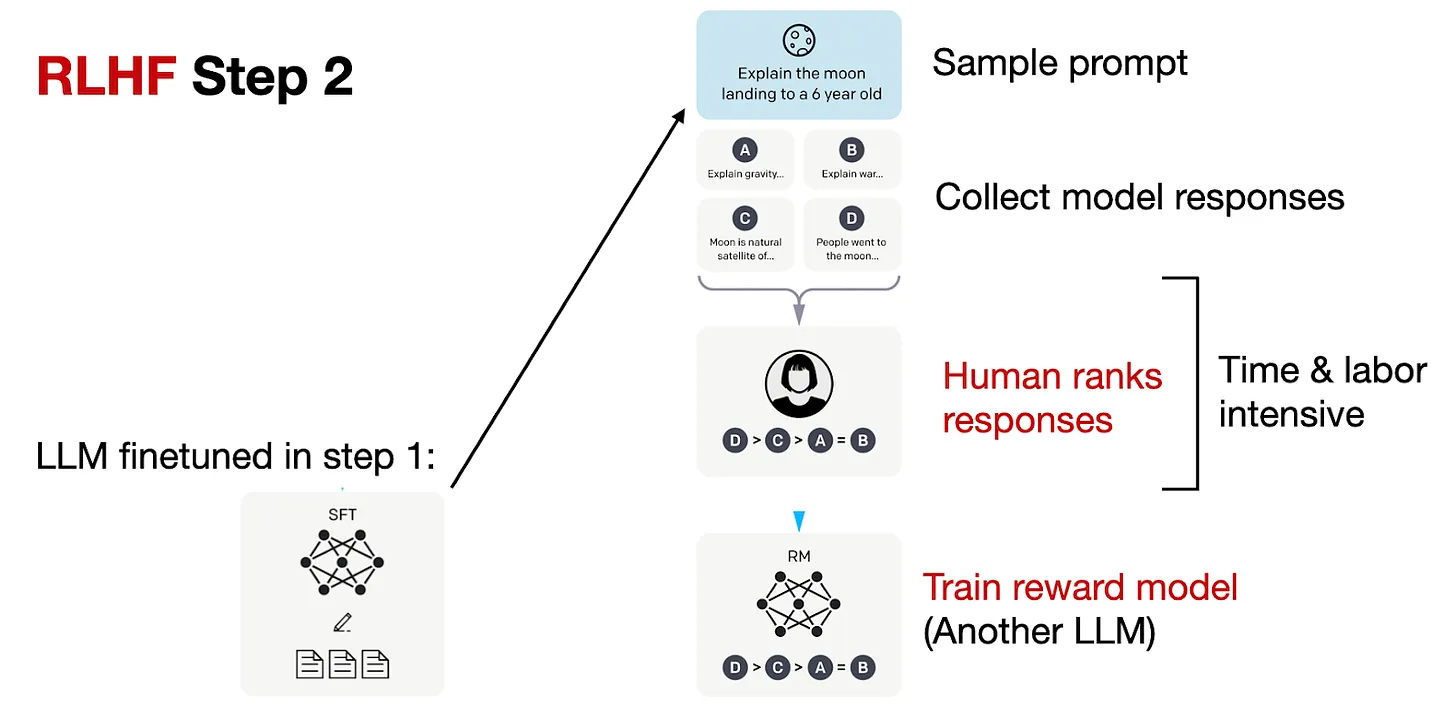
Trong bước 2, chúng ta sử dụng model đã được SFT để tạo 1 reward model. Trong hình trên, với mỗi prompt, ta sẽ tạo ra từ 4 đến 9 câu trả lời từ LLM được SFT trong bước trước. Sau đó, ta sẽ sử dụng "sức người" để ranking các câu trả lời này theo sở thích của họ. Mặc dù quá trình ranking này tốn thời gian, nhưng có thể đỡ vất vả hơn so với việc tạo ra tập dữ liệu cho SFT. Lý do là chúng ta chỉ cần chọn câu nào mình thích thôi, thay vì phải gõ phản hồi cho từng câu để làm dữ liệu như SFT
Sau quá trình trên, chúng ta đã có 1 tập dữ liệu đã được ranking. Khi này, ta có thể thiết kế một mô hình phần thưởng (reward model) để đưa ra điểm thưởng cho giai đoạn tối ưu tiếp theo trong bước 3 của RLHF. Reward model (RM) này thường được xây dựng từ mô hình LLM trong bước SFT trước đó.
Để chuyển model SFT sang RM, output layer (next-token classification layer) của model SFT được thay bằng regression layer với 1 node đầu ra duy nhất.
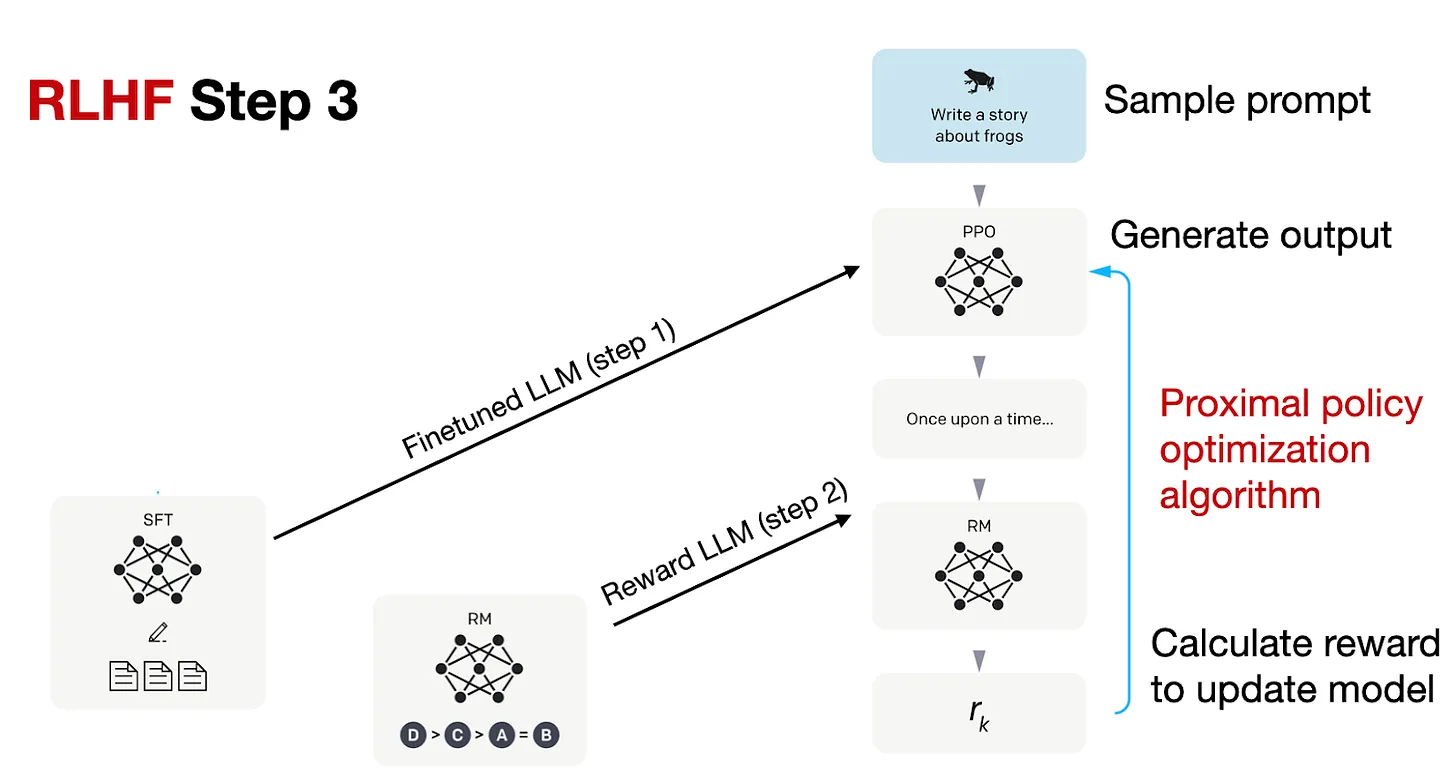
Trong bước thứ 3, RLHF pipeline sử dụng RM để finetune cho mô hình SFT trước đó, các bạn có thể xem trong hình trên. Tại bước cuối cùng trong giai đoạn này, ta thực hiện cập nhật mô hình SFT sử dụng proximal policy optimization (PPO) dựa vào reward score từ RM.
RLHF trong Llama 2
RLHF trong ChatGPT thì đã có nhiều bài viết rồi, vậy thì RLHF trong Llama 2 thì như nào nhỉ ?
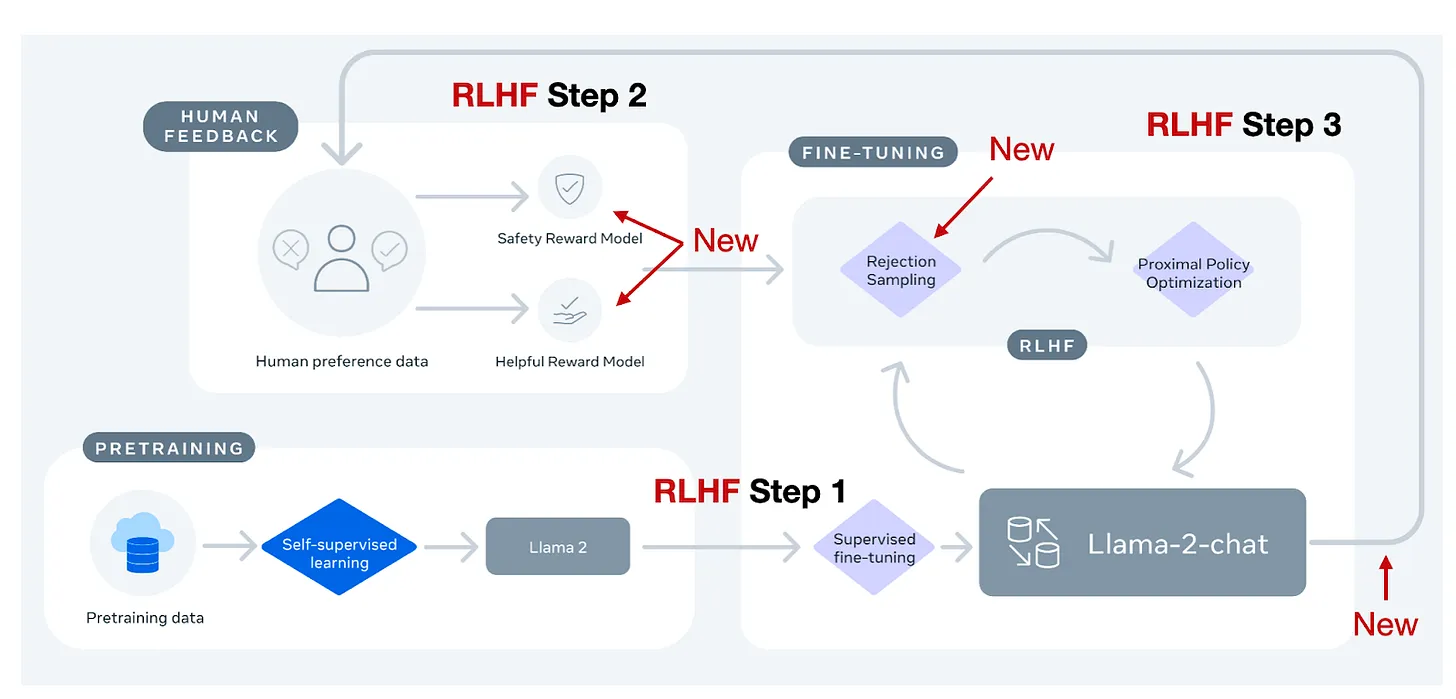
Quy trình RLHF của Llama 2 được thể hiện trong hình trên. Các bạn có thể thấy, Llama-2-chat có bước SFT giống bước 1 của RLHF trong InstructGPT. Tuy nhiên, trong bước 2 của RLHF, 2 RM được tạo ra thay vì chỉ 1.
Ngoài ra, mô hình Llama-2-chat liên quan tới nhiều bước hơn, với các RM được cập nhật dựa trên các lỗi mới phát sinh từ mô hình Llama-2-chat. Ở đây, ta cũng có thêm 1 bước Rejection Sampling.
Margin Loss
Một điểm khác nữa không được thể hiện trong hình trên là cách ranking các phản hồi của mô hình để xây dựng RM. Trong phương pháp InstructGPT chuẩn đối với PPO RLHF ở phần trước, các tác giả thu thập 4-9 phản hồi đầu ra để tạo ra các cặp so sánh.
Ví dụ, nếu một nhân viên gán nhãn xếp hạng 4 phản hồi đầu ra (A-D), chẳng hạn như A < C < D < B, thì họ phải thực hiện gán nhãn 6 cặp so sánh:
-
A < C
-
A < D
-
A < B
-
C < D
-
C < B
-
D < B
Về cách gán nhãn thì ở Llama 2 cũng giống với InstructGPT. Điểm khác là thay vì cho 4-9 phản hồi để so sánh như InstrucGPT thì với Llama 2, ta chỉ được cho 2 phản hồi.
Ngoài ra điều mới mẻ ở đây là với mỗi lần so sánh, một nhãn "margin" (có giá trị từ "tốt hơn đáng kể" đến "tốt hơn không đáng kể") được thu thập. Ví dụ, phản hồi A tốt hơn đáng kể phản hồi B hoặc phản hồi A tốt hơn nhưng không đáng kể phản hồi B.
Thông tin này có thể được sử dụng trong binary ranking loss bằng cách thêm một tham số margin để tính toán distance giữa hai phản hồi.
Trong khi InstructGPT sử dụng cross entropy-based ranking loss để huấn luyện RM với công thức sau:
thì Llama-2 thêm vào một giá trị có vai trò như một hàm rời rạc cho ranking như sau:
Trong đó:
-
là điểm số đầu ra (scalar score) cho prompt x và phản hồi (generated response) y
-
là model weight
-
là hàm logistic sigmoid
-
là phản hồi được ưu tiên chọn bởi đội gán nhãn
-
là phản hồi bị từ chối chọn bởi đội gán nhãn
Ví dụ, margin "m(r)" lớn sẽ làm cho sự chênh lệch giữa reward của các phản hồi được ưu tiên và bị từ chối nhỏ hơn, dẫn đến loss lớn hơn -> làm cho gradient lớn hơn, và do đó thay đổi mô hình nhiều hơn trong quá trình cập nhật policy gradient.
2 reward model
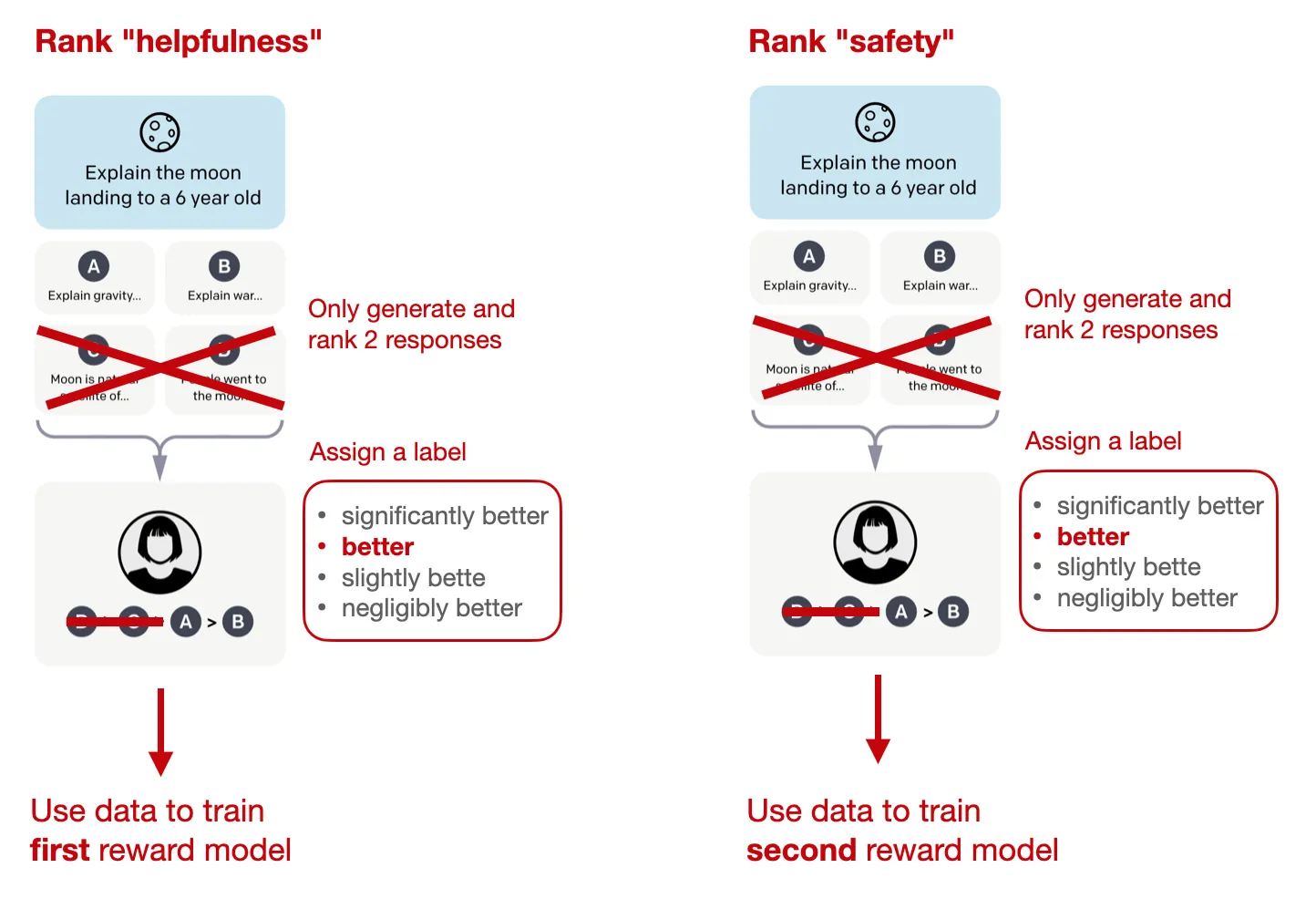
Như đã đề cập ở phần trước, Llama 2 sử dụng 2 reward model thay vì chỉ 1. Ở đây, ta có:
- 1 reward model được dùng để đánh giá tính hữu ích (helpfulness) của câu trả lời.
- 1 reward model được dùng để đánh giá tính an toàn (safety) của câu trả lời.
Hàm reward cuối cùng dùng để tối ưu mô hình là 1 kết hợp tuyến tính của 2 reward này.
Rejection sampling
Nhóm tác giả của Llama 2 sử dụng một training pipeline liên tục chạy và lặp đi lặp lại để tạo ra nhiều mô hình RLHF (từ RLHF-V1 đến RLHF-V5). Thay vì chỉ dựa vào phương pháp RLHF với PPO đã nhắc ở phần trước, họ sử dụng hai thuật toán cho RLHF: PPO và rejection sampling.
Trong phương pháp rejection sampling, K output được lấy ra và output có reward cao nhất được chọn để cập nhật gradient trong bước optimization, như minh họa dưới đây.
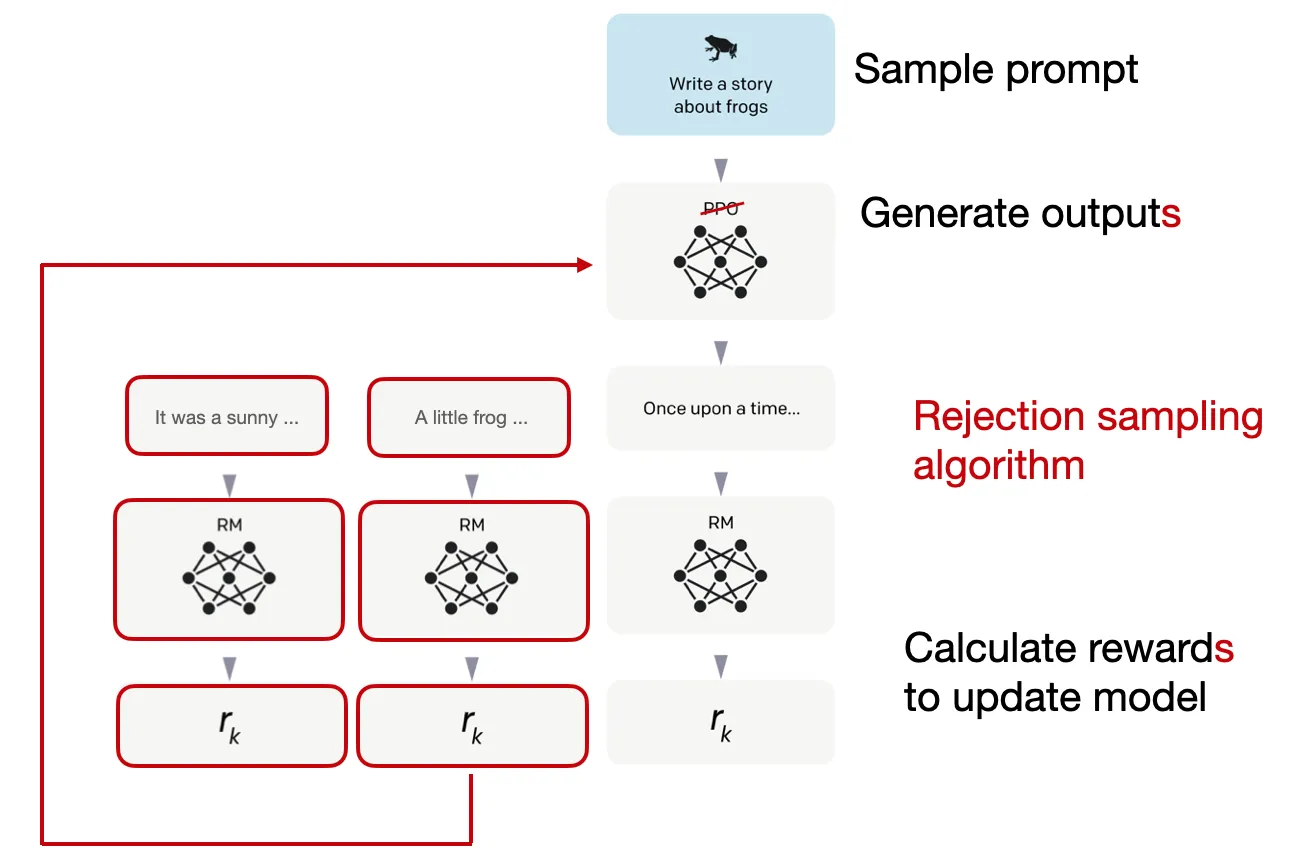
Phương pháp rejection sampling nhằm chọn các sample có reward score cao trong mỗi lần lặp. Do đó, mô hình sẽ thực hiện finetune với các mẫu có reward cao hơn so với PPO, mỗi lần cập nhật chỉ dựa trên 1 sample.
Sau bước SFT, các mô hình được train hoàn toàn bằng rejection sampling, sau đó kết hợp cả rejection sampling và PPO.
Nhóm tác giả đã vẽ biểu đồ hiệu suất của mô hình qua các giai đoạn RLHF, cho thấy rằng các mô hình finetuning qua RLHF cải thiện cả về độ an toàn và độ hữu ích.
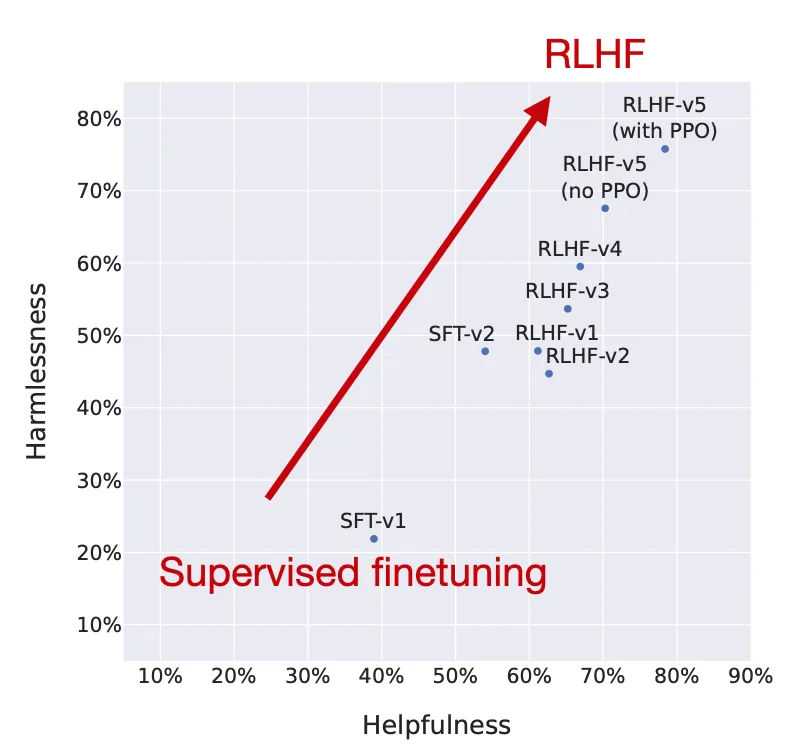
Lưu ý rằng, ở bước cuối cùng, các nhà nghiên cứu sử dụng PPO sau khi những mô hình trước đó đã được cập nhật thông qua rejection sampling. Như so sánh giữa "RLHF-v5 (có PPO)" và "RLHF-v5 (không PPO)" trong biểu đồ ở trên cho thấy, một mô hình được đào tạo với PPO ở giai đoạn cuối tốt hơn một mô hình chỉ được đào tạo với rejection sampling.
Kết luận
Trong bài viết trên, chúng ta đã biết được tổng thể một pipeline finetuning sử dụng RLHF. Chúng ta có thể thực hiện nhiều chiến lược RLHF khác nhau, với sự thay đổi ở từng bước để cải thiện mô hình. InstructGPT và RLHF của Llama 2 về ý tưởng cơ bản là giống nhau. Tuy nhiên, chỉ cần thêm thắt 1 chút kỹ thuật ở các bước cuối cũng cho kết quả ấn tượng hơn rất nhiều
All rights reserved
